Introduction
Storing data is one thing; storing meaningful, useful, correct data is quite another. While meaning and utility are themselves subjective qualities, correctness at least can be logically defined and enforced. Types already ensure that numbers are numbers and dates are dates, but can't guarantee that weight or distance are positive numbers or prevent date ranges from overlapping. Tuple, table, and database constraints apply rules to data being stored and reject values or combinations of values which don't pass muster.
Constraints don't render other input validation techniques useless by any means, even when they test the same assertions. Time spent trying and failing to store invalid data is time wasted. Violation messaging, like assert in systems and application programming languages, only reveals the first problem with the first candidate record in much more detail than anyone not immediately involved with the database needs. But as far as the correctness of data is concerned, constraints are law, for good or ill; anything else is advice.
On tuples: not null, default, and check
Non-null constraints are the simplest category. A tuple must have a value for the constrained attribute, or put another way, the set of allowed values for the column no longer includes the empty set. No value means no tuple: the insert or update is rejected.
Protecting against null values is as easy as declaring column_name COLUMN_TYPE NOT NULL in CREATE TABLE or ADD COLUMN. Null values cause entire categories of problems between the database and end users, so reflexively defining non-null constraints on any column without a good reason to allow nulls is a good habit to get into.
The provision of a default value if nothing is specified (by omission or an explicit NULL) in an insert or update is not always considered a constraint, since candidate records are modified and stored instead of rejected. In many DBMSs, default values may be generated by a function, although MySQL does not allow user-defined functions for this purpose.
Any other validation rule which depends only on the values within a single tuple can be implemented as a CHECK constraint. In a sense, NOT NULL itself is a shorthand for CHECK (column_name IS NOT NULL); the error message received in violation makes most of the difference. CHECK, however, can apply and enforce the truth of any Boolean predicate over a single tuple. For example, a table storing geographic locations should CHECK (latitude >= -90 AND latitude < 90), and similarly for longitude between -180 and 180 -- or, if available, use and validate a GEOGRAPHY data type.
On tables: unique and exclusion
Table-level constraints test tuples against each other. In a unique constraint, only one record may have any given set of values for the constrained columns. Nullability can cause problems here, since NULL never equals anything else, up to and including NULL itself. A unique constraint on (batman, robin) therefore allows for infinite copies of any Robinless Batman.
Exclusion constraints are only supported in PostgreSQL and DB2, but fill a very useful niche: they can prevent overlaps. Specify the constrained fields and the operations by which each will be evaluated, and a new record will only be accepted if no existing record compares successfully with each field and operation. For instance, a schedules table can be configured to reject conflicts:
Upsert operations such as PostgreSQL's ON CONFLICT clause or MySQL's ON DUPLICATE KEY UPDATE use a table-level constraint to detect conflicts. And like non-null constraints can be expressed as CHECK constraints, a unique constraint can be expressed as an exclusion constraint on equality.
The primary key
Unique constraints have a particularly useful special case. With an additional non-null constraint on the unique column or columns, each record in the table can be singularly identified by its values for the constrained columns, which are collectively termed a key. Multiple candidate keys can coexist in a table, such as users still sometimes having distinct unique and non-null emails and usernames; but declaring a primary key establishes a single criterion by which records are publicly and exclusively known. Some RDBMSs even organize rows on pages by the primary key, called for this purpose a clustered index, to make searching by primary key values as fast as possible.
There are two types of primary key. A natural key is defined on a column or columns "naturally" included in the table's data, while a surrogate or synthetic key is invented solely for the purpose of becoming the key. Natural keys require care -- more things can change than database designers often credit, from names to numbering schemes. A lookup table containing country and region names can use their respective ISO 3166 codes as a safe natural primary key, but a users table with a natural key based on mutable values like names or email addresses invites trouble. When in doubt, create a surrogate key.
If a natural key spans multiple columns, a surrogate key should always at least be considered since multi-column keys take more effort to manage. If the natural key suits, however, columns should be ordered in increasing specificity just as they are in indexes: country code then region code, rather than the reverse.
The surrogate key has historically been a single integer column, or BIGINT where billions will eventually be assigned. Relational databases can automatically fill surrogate keys with the next integer in a series, a feature usually called SERIAL or IDENTITY.
An autoincrementing numeric counter is not without drawbacks: adding in records with pregenerated keys can cause conflicts, and if sequential values are exposed to users, it's easy for them to guess what other valid keys might be. Universally Unique Identifiers, or UUIDs, avoid these weaknesses and have become a common choice for surrogate keys, although they're also much bigger in-page than a simple number. The v1 (MAC address-based) and v4 (pseudorandom) UUID types are most frequently used.
On the database: foreign keys
Relational databases implement only one class of multi-table constraint, the
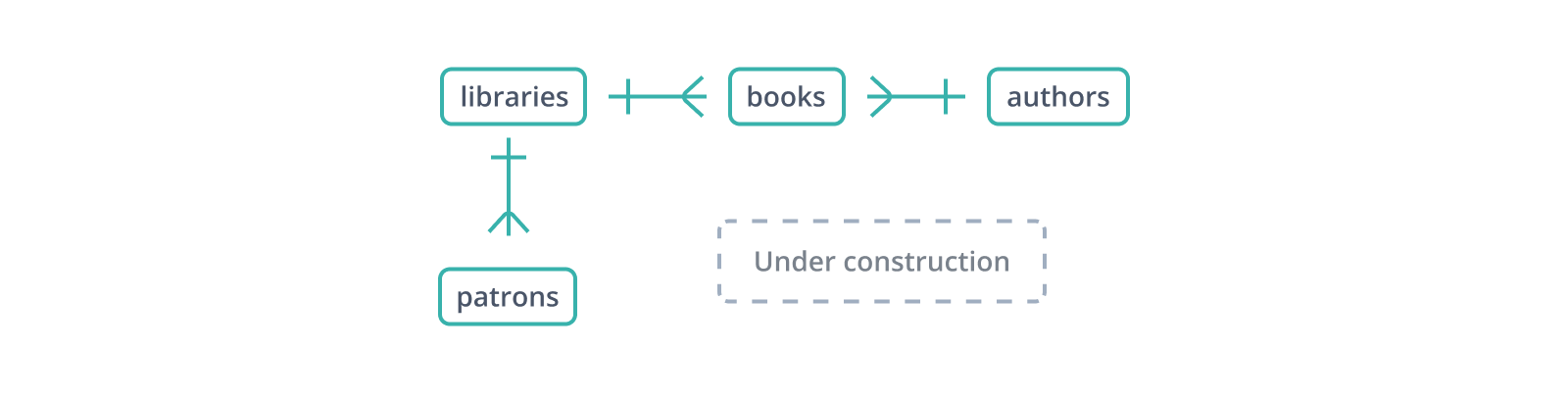
This informal "entity-relationship diagram" or ERD shows the beginnings of a schema for a database of libraries and their collections and patrons. Each edge represents a relationship between the tables it connects. The | glyph indicates a single record on its side, while the "crow's foot" glyph represents multiple: a library holds many books and has many patrons.
A foreign key is a copy of another table's primary key, column for column (a point in favor of surrogate keys: only one column to copy and reference), with values linking records in this table to "parent" records in that. In the schema above, the books table maintains a library_id foreign key to libraries, which hold books, and an author_id to authors, who write them. But what happens if a book is inserted with an author_id that doesn't exist in authors?
If the foreign key is not constrained -- i.e., it's just another column or columns -- a book can have an author who doesn't exist. This is a problem: if someone tries to follow the link between books and authors, they wind up nowhere. If authors.author_id is a serial integer, there's also the possibility that no-one notices until the spurious author_id is eventually assigned, and you wind up with a particular copy of Don Quixote attributed first to nobody known and then to Pierre Menard, with Miguel Cervantes nowhere to be found.
Constraining the foreign key can't prevent a book from being misattributed should the erroneous author_id point to an existing record in authors, so other checks and tests remain important. However, the set of extant foreign key values is almost always a tiny subset of the possible foreign key values, so foreign key constraints will catch and prevent most wrong values. With a foreign key constraint, the Quixote with a nonexistent author will be rejected instead of recorded.
Is this where the "relational" in "relational database" comes from?
Foreign keys create relationships between tables, but tables as we know them are mathematically relations among the sets of possible values for each attribute. A single tuple relates a value for column A to a value for column B and onward. E.F. Codd's original paper uses "relational" in this sense.
This has caused no end of confusion and will likely continue to do so in perpetuity.
For certain values of correct
There are many more ways in which data may be incorrect than addressed here. Constraints help, but even they are only so flexible; many common intra-table specifications, like a limit of two or higher on the number of times a value is allowed to appear in a column, can only be enforced with triggers.
But there are also ways in which the very structure of a table can lead to inconsistencies. To prevent these, we'll need to marshal both primary and foreign keys not just to define and validate but to normalize the relationships between tables. First, though, we've barely scratched the surface of how the relationships between tables define the structure of the database itself.
If you want to learn more about what data modeling means in the context of Prisma, visit our conceptual page on data modeling.
You can also learn about the specific data model component of a Prisma schema in the data model section of the Prisma documentation.
FAQ
A tuple is a data structure that stores a specific number of elements. These elements may include integers, characters, strings, or other data types.
Tuples are static and cannot be modified, typically resulting in lower memory requirements than arrays.
A typical tuple uses numerical indexes to access its members.
A named tuple differs in that its members are assigned names in addition to the numerical index. This can be beneficial in instances where a tuple has a lot of fields and is constructed far from where it is being used.
In the context of a relational database, a tuple can be thought of as a single record or row of that database.
For example, in a customer database a row might include a customer’s first name, last name, phone number, email, and shipping address. All of this information together can be thought of as a tuple.
A FOREIGN KEY is a field or collection of fields in one table that often refers to the PRIMARY KEY of another table.
However, it can also refer to any unique column that is also not null.
Relational databases use primary and foreign keys to establish connections between tables in a database. These keys facilitate access to one table from another within a database.
Primary keys can also be generally useful for uniquely addressing individual records even without any foreign keys.
