Data modeling
Tables, tuples, types
Introduction
Calling tables the "basic building block" of relational databases is a little reductive. While it's hard to miss the mark by much in drawing up a list of each datum you're interested in and declaring this an integer, that a date, and so forth, effective relational database design depends first and foremost on well-thought-out and well-formulated table designs. Tables must be legible to users and developers, with their schemas making sense out of the information they represent. And while databases go to considerable lengths to handle physical storage unsupervised, understanding how this process works and designing for it is especially important for "wide" tables with records containing many large values.
One table generally, but not always, groups aspects of a single concept: a person's name and password, a hotel reservation's check-in and check-out dates, or a shipment's source, destination, status, and tracking number. The art and science of determining where one table should leave off and another pick up is called normalization, which we'll cover in a future installment.
Ineffective table designs come in myriad forms. They may fail to capture important characteristics of the subject the table represents, restrict too far or not enough what values are considered valid in a
Naming things
Opinions about how to approach the nuts and bolts of naming in a database are a dime a dozen. No two people agree on all points, and one's allegiance to singular or plural table names (or, for that matter, uppercasing or lowercasing keywords) is largely a function of habit. RDBMS flavor also plays a role, with PostgreSQL heavily favoring snake_case names while UpperCamelCase is a telltale sign of SQL Server.
For my part, I use snake_case, prefix booleans with is_ and suffix dates with _at, use plural for tables and singular for columns, and name junction tables leader_followers. But as any guide worth listening to will tell you: the single most important thing isn't that you do what I do, it's that you be consistent, either with your own preferences or with the conventions of an existing database you're working in.
Storage: making records out of ones and zeroes
Modern RDBMSs abstract most of the intricate details of how data are arranged and stored, most of the time. The basic unit of storage is the page, a uniformly-sized logical block of records and metadata corresponding to a segment of physical storage space: 2kb in Oracle, 4 in DB2, 8 in SQL Server and PostgreSQL, 16 with MySQL's InnoDB. When the database reads or writes data, it does so page by page rather than record by record.
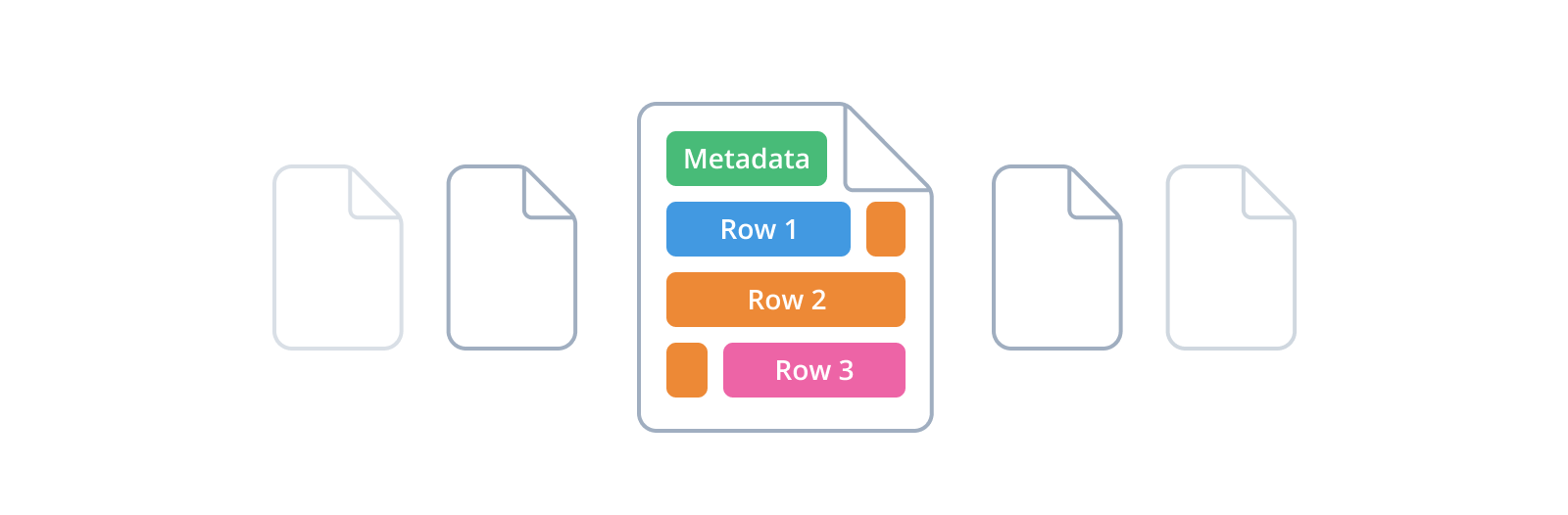
It's possible for a
All these techniques incur a performance cost, since SQL statements are faster the fewer pages have to be read or written, or pointers followed. But there's another way ineffective allocation of pages can hurt performance: when most or all of a table's tuples take up just over half a page, the remaining space goes unused. Because it's still allocated, it bloats the table's disk usage, and a query that retrieves or affects n rows must load all n pages.
Most enterprise relational databases, Postgres excepted, also manage pages in groups called extents and group extents in turn under segments. This more complicated strategy helps keep rows in order, which can speed up searches. Postgres has its own tricks here, such as using visibility maps to support "index-only queries" which skip looking at the table's pages entirely. Indexes themselves are also stored in pages, although these have their own organization.
The chief innovation of column-oriented databases like Cassandra and HBase is in abandoning the tuple-by-tuple physical page layout to speed up retrieval of huge amounts of data column by column. This is by no means a free lunch, however, as many basic RDBMS capabilities depend on tuples in themselves.
Data types
Types serve multiple purposes for relational databases. Like types anywhere else, they establish a contract: books.title is text and always text, recipients.postcode is a number and always a number -- which latter assumption fails the moment a recipient lives in the UK, Canada, or any of several other countries (postcodes are properly text).
But equally important to an RDBMS is that types define sizes, and therefore determine page layout. The SQL standard defines an integer as four bytes, whether a specific four bytes represents an undetermined value (NULL), zero, or two billion. Text declared as a CHAR of a fixed length n always takes up n bytes, and shorter values are padded with spaces until they're long enough. Sometimes the spaces are even returned in SELECTs, as in SQL Server.
Not all types define a fixed length, however. The standard VARCHAR type establishes a maximum length instead, and values are not padded in the manner of CHAR. Variable-length types mean variable-length tuples, which in turn allow the database more flexibility in fitting those tuples into pages.
In all, the SQL standard defines a multitude of types, classed into numeric, boolean, date and time, time intervals, text, binary, all the way up to XML and JSON. Faithful adherence to the standard varies, as usual, across implementations. Some add non-standard data types on top, with currency, geometry and geography, ranges, and more making appearances.
Choosing a data type
Defining the appropriate type for a datum is usually straightforward. If you're using PostgreSQL, care about exactitude, and have values running to eight decimal places, that rules out floating-point types and indicates the scale of the NUMERIC you'll need. Most other questions in this vein resolve similarly.
The major complication is text. The ISO-standard variable-length character type VARCHAR or the Unicode-enabled NVARCHAR in SQL Server suit most purposes, with the fixed-size CHAR relegated to specific cases of fixed-length strings; the harder decision is the appropriate length. Sometimes you get lucky, and the well-known, externally-imposed limits of SMS let you get away with restricting people to 140-byte posts for long enough they get used to it. But even Twitter's determination to keep the "micro" in "micro-blog" eventually relaxed somewhat, and meanwhile a twenty-byte city_name field is practically begging for someone from Llanfairpwllgwyngyllgogerychwyrndrobwllllantysiliogogogoch to turn up.
Space is cheap, unused space doesn't count with VARCHARs, and most tables are unlikely even to get close to a single tuple per page. It's rarely worth haggling over length byte for byte instead of choosing a nice round number like the next order of magnitude (here, 100) or approximate power of 2 (255 is notably also a built-in limit in older database software) above the longest plausible value.
PostgreSQL is a special case: both CHAR(n) and VARCHAR(n) are recommended against, unless a length limit is specifically desired. Instead, the nonstandard TEXT type, powered by the varlena (variable-length array) data structure, offers unbounded text storage.
"Large object" types in most RDBMSs are a class of binary and text data types useful for such values as images and documents, which are frequently long enough to make on-page storage impractical. Reading from or writing to large object storage is an extra step on top of reading or writing the page, so inline storage remains preferable at the scale of names, serial numbers, and summaries. The binary sort are collectively referred to as BLOBs (binary large object) in most RDBMSs, although Postgres' sole varlena-enabled binary type is BYTEA. Large text types may go by TEXT or CLOB, or in SQL Server VARCHAR(MAX).
It bears mentioning here that relational databases are not especially good at being file servers. Images, audio or video files, text documents, and the like are usually better off in systems designed to store and serve them. But where these data, unstructured as far as the database is concerned, are directly germane to specific records -- think binary test output files recorded for a mechanical part being tracked through manufacturing or the source code of web pages being scraped and analyzed -- large object types suffice.
Semi-structured data types
For most of the history of relational databases, substrings and the like have been the limit of delving into large objects, which are otherwise structurally opaque. What data types like JSON and XML ask is "what if they weren't?". Both JSON and XML documents are hierarchical, something earlier database designers had to break out the foreign keys and JOINs to accommodate. Moreover, semi-structured types describe their own schemas. The only requirement the database can impose is that values be correctly formed, whatever their contents.
Hierarchies are not uncommon, even in information systems mostly operating by relational rules. An addressable, processable hierarchy-as-data-type makes storage and retrieval about as simple as possible, and allows blending relational and document strategies to good effect. A table that does little more than wrap a document field can even make a helpful prototyping tool in the especially early stages of defining the schema. And while SQL is unlikely ever to match e.g. JavaScript's facility with a format named after it, the functionality that exists around these types (hierarchic or otherwise) opens up a lot of possibilities for database programming.
Collections and more
Some values are only meaningful in combination: a low and a high bound, a start and an end date, an ordered list of numbers or strings. Ranges can be simulated by decomposition into e.g. started_at and ended_at fields, and in strictly relational terms an array is properly normalized into a separate table with a foreign key, but the convenience of treating a range or an array as a single value to test containment, overlap, and other specialized operations can't be underestimated. Range types are thus far exclusive to PostgreSQL, and both Postgres and Oracle support arrays.
Another common case is for a column to represent one of a well-defined and relatively static set of values: status codes, continents, and the like. CHAR and VARCHAR take up a lot of redundant space used this way and must be carefully checked and constrained to prevent meaningless values from making it in; INT codes are safer, but always have to be looked up. Many programming languages offer readable names for numeric codes in the form of enumerations or enums. PostgreSQL and MySQL both support these as column data types, albeit in slightly different ways, with MySQL's operating like constraints on individual columns while Postgres' enums are reusable.
Build your own
User-defined types in SQL Server or Oracle, composite types in PostgreSQL: they exist. A POINT type, for instance, can ensure that its x and y values are inseparable, and the possibilities of nesting tuples inside tuples rapidly get more complex. Dealing with custom data types isn't always easy, especially from outside the database, so defining data models in terms of built-in or extension-provided types is usually to be preferred.
More than complete
A list of each datum you're interested in, this an integer, that a date, and so forth. Types and tuples, columns and rows, make a table functionally complete. But there's more than completeness to think about: how can a table ensure that the information it records is correct?
Coming up in Correctness and Constraints, we'll cover the tools relational databases use to define and enforce correctness at all levels of data storage.
If you want to learn more about what data modeling means in the context of Prisma, visit our conceptual page on data modeling.
You can also learn about the specific data model component of a Prisma schema in the data model section of the Prisma documentation.
