Introduction
Foreign keys describe relationships, and the entity-relationship diagrams (ERDs) introduced in Correctness and Constraints map networks or graphs of those foreign keys. In these examples, there are only a few tables and relationships among them, but a visual layout is still a useful reference when it comes time to make sure every required relationship is accounted for. With larger databases, ERDs are invaluable, full stop. Many database clients have built-in tools to generate diagrams, although manual adjustment is usually required to make them readable.
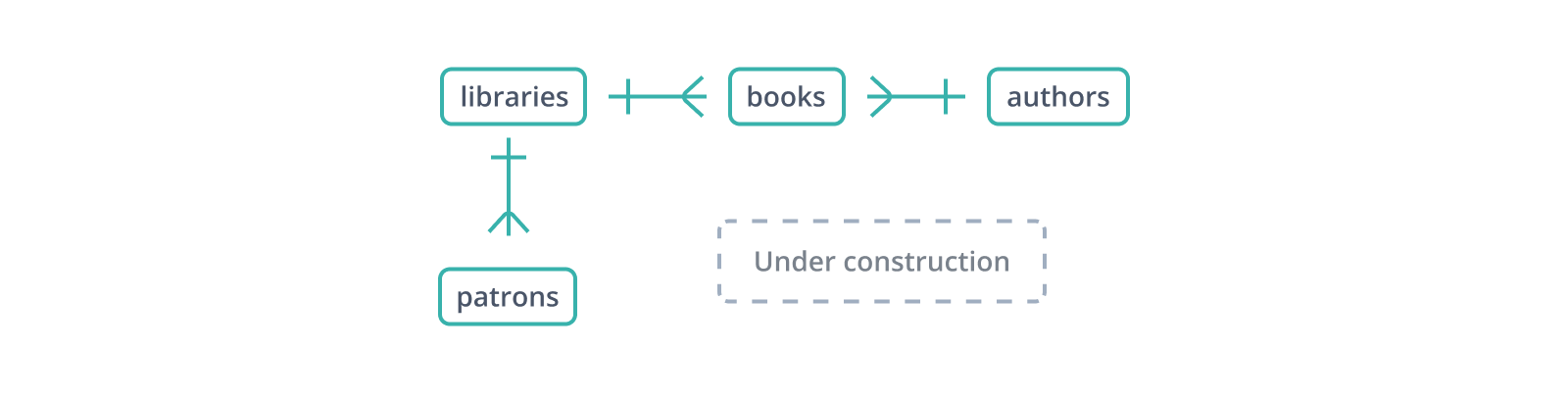
Several ERD notations exist. The full "crow's foot" notation, one of the oldest and most influential, defines symbols for 0 (a ring), 1 (a dash), or many (the eponymous crow's foot, as above) records. Each line represents a relationship between two tables and has not just one but two of these symbols on each end, with each pair establishing the minimum and maximum for that side.
This attention to detail is at least in part an historical artifact from the days when running a database server on a workstation would be unheard of, and in the modern era few ERDs are that formally specified. As with the diagrams here, a symbol for "one at most" and a symbol for "zero to many" are enough to get the gist across, and there's rarely a need for a level between that and sharing the SQL scripts themselves anymore.
Cascading behaviors
Inserting an invalid author_id into books isn't the only way to violate a foreign key constraint: changes to authors can also invalidate existing data in books. Back in Correctness and Constraints, unenforced foreign keys led to a copy of Don Quixote with a spurious author_id. How to resolve the contradiction between Pierre Menard and Miguel Cervantes?
If the Menard record could be deleted from authors, the copy of the Quixote in question would no longer have a valid author_id. The database rejects this, as violations cannot be allowed either from the child or the parent table. To get rid of Pierre Menard, one must first dispose of Don Quixote, either by deleting it or by changing its author_id.
As the web of constrained relationships grows larger, cleaning up such dependent records becomes more and more complicated. Deleting an author entails deleting all their books; deleting a library requires the same, plus removing its patrons -- and any table with a foreign key to books or patrons must be deleted first of all, lest those foreign key constraints be violated in turn.
A DELETE against a parent table is often intended to prune an entire tree of relationships: a library and its books and its patrons, in one fell swoop (sometimes it isn't meant to do this, which makes knowing where your CASCADEs are very important!). Since foreign key constraints reify these relationships, making of them objects to be acted upon, they can also help automate responses to changes in the parent table. A constraint declaring ON DELETE SET NULL will void the first foreign key values only, without traversing the relationship graph any further. ON DELETE CASCADE ensures that a DELETE to authors will automatically delete those authors' books as well, and onward through any foreign key that declares books a parent table.
On occasion, natural primary key values may also change as standards and formats update or as the assumption that the natural key was immutable turns out to have been incorrect. Most RDBMSs support an ON UPDATE CASCADE behavior for this eventuality.
The future is here and everything needs to be destroyed
Even if real libraries or authors are never supposed to be deleted (only deactivated, or "soft-deleted"), both automated and manual tests often require a fresh, empty database up front or even for each individual test. Dropping and recreating the database breaks connections, requires elevated permissions, and is the slowest possible solution to boot.
The usual recourse is a "teardown" function or script which deletes anything previous tests might have inserted into the database, table by table. Without CASCADE directives, these deletions must be arranged carefully in a topological sort order around the relationship graph to avoid ever violating a foreign key constraint. With CASCADEs, teardown mostly takes care of itself once you delete records at the center of each of the database's various relationship graphs.
Key positioning
Both libraries and authors preexist any useful record of the books they lend and write respectively. These cases correspond to the "has-a" relationship type in object-oriented programming, which in database design requires the foreign key to be stored in the dependent table, books.
Other cases aren't so clear. Imagine that some books are themselves on loan to libraries from outside collections, and that their original books have a provenance_id, or should the provenances table have a book_id column?
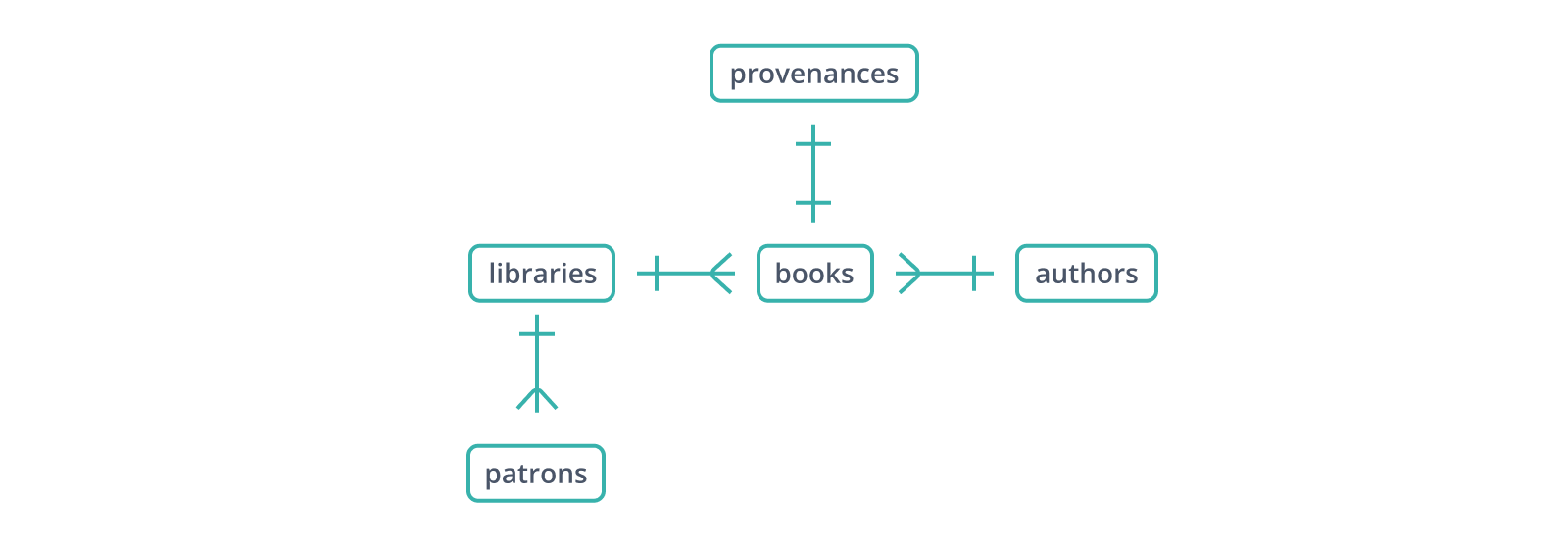
Both solutions will serve the purpose of tracking provenance. However, in the case of books.provenance_id, there's no way to follow the link back to a book from its provenance -- one would have to search books for a matching provenance_id. And since most books have no special provenance, most values for provenance_id will be NULL.
In this situation, the provenances.book_id approach is clearly superior. The book_id link is traceable, columns are used efficiently, and provenances.book_id is even a primary key, since a single book shouldn't have come to a library from more than one place. De Haan and Koppelaars would call provenances a specialization of books, a table which adds supplementary information to records in its parent identified by the same primary key. The connection between books and provenances is a "one-to-one" relationship, since only one of any book_id value can exist in either table.
Properly speaking, provenance includes the entire chain of custody of an artifact, not just who had it last. If necessary for our purposes, this complicates the picture somewhat: with multiple records per book in provenances, book_id is provenances table in which records are not (or not only) identified by the foreign key is no longer a specialization, but the "many" side of a "one-to-many" relationship -- or, viewed from the other direction, of a "many-to-one".
Many-to-many relationships
Elsewhere in the example schema, patrons have a library_id value. This expresses a very important -- and likely a very wrong -- assumption: any person will patronize one library and one library only. If someone goes to another library, they'll have to enter all their information all over again. This violates another important assumption, namely, that a single record in patrons corresponds to a single person. Both can't be true.
There's a second problem with a similar solution: we aren't yet tracking who's checked a book out. A single patron can borrow many books, while a single book can be checked out many times. Structurally, this is nearly identical to the case of a single library having many patrons, who themselves may borrow from multiple libraries.
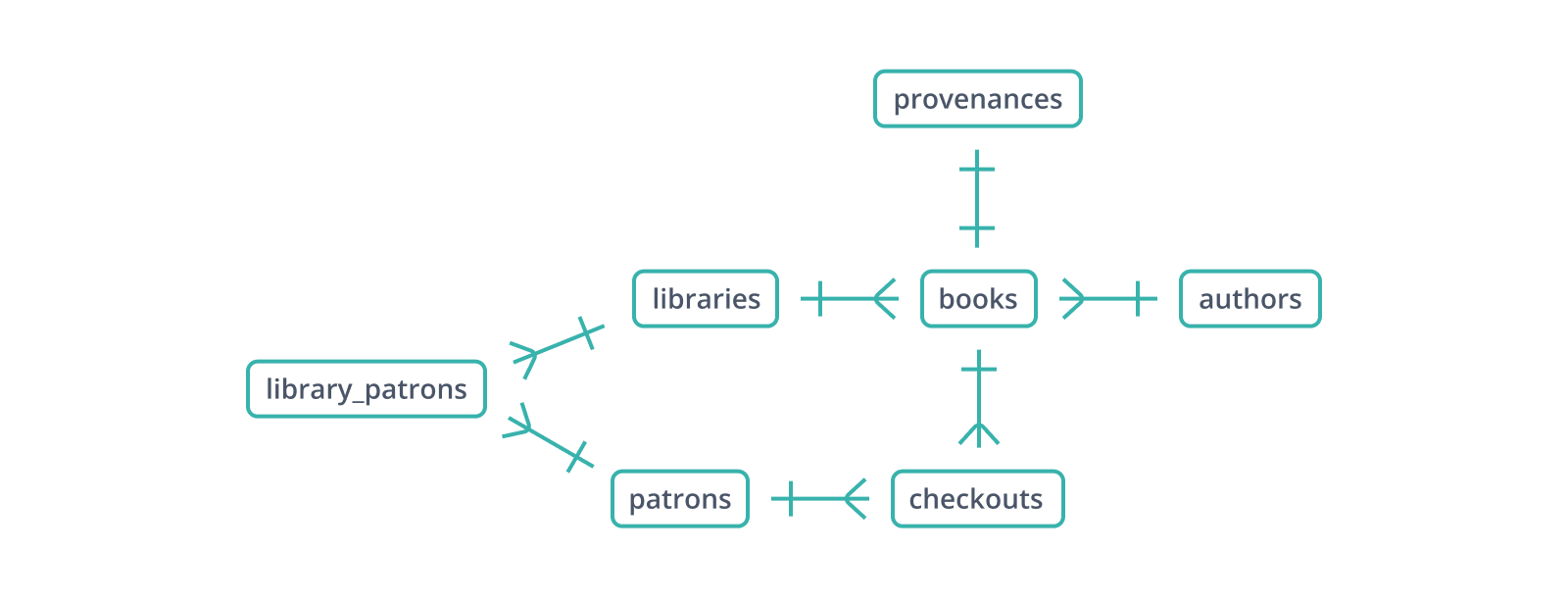
A "many-to-many" relationship has to be represented in a dedicated table, often called a junction or bridge table, among other names. The junction table maintains foreign keys to each table it mediates, making it the "many" side of its relationships to those tables. A primary key across each foreign key prevents duplicates of the same relationship.
library_patrons, a textbook example of a junction table, looks like this:
checkouts, you might have noticed, doesn't follow the same naming convention as library_patrons -- it's not patron_books or vice versa. That's because it's more than a junction table. Like library_patrons, checkouts maintains foreign keys to the tables it connects in a many-to-many relationship, but it must also include information about each patron-book connection: the date checked out, the date due or returned, whether an extension has been granted. It's also perfectly possible for someone to check out the same book multiple times, so (patron_id, book_id) is not a viable primary key.
Building blocks
Many-to-many relationships are only one possible composition of the two primary relationship types. They're common enough that diagrams often omit library_patrons-style junction tables entirely in favor of representing both ends with a "many" symbol. But every network of connections among tables, no matter how complicated, is reducible into its constituent one-to-one and one-to-many relationships.
Boundaries
A single database may (and often does) contain multiple networks of foreign key relationships. The reverse, however, is usually not true. MySQL and MariaDB alone among the popular relational databases conflate schemas and databases, and therefore allow cross-database foreign keys as long as both databases are hosted on the same server. Others do not.
We'll come back to organizing tables in databases and in schemas within databases later, but it's useful to consider a multi-table relationship graph the indivisible unit of database layout in the same way that the combined attributes of a given concept form the basis for a table layout.
If you want to learn more about what data modeling means in the context of Prisma, visit our conceptual page on data modeling.
You can also learn about the specific data model component of a Prisma schema in the data model section of the Prisma documentation.
