Managing databases
Troubleshooting database outages and connection issues
Introduction
A suspected database outage can be a stressful event for everyone. Users become frustrated and worry their data might be lost, developers scramble to find the cause, and company stakeholders count every minute that might incur revenue loss.
Getting your database back to a healthy state in the event of an outage is priority one. However, it can be difficult to even reason about what the problem might be in the midst of such a stressful event. This article aims to help guide you through some of the most common reasons your database might be down and what you can do to fix it.
The article covers a variety of areas to look for when dealing with database outages, including:
| Problem | Potential Issues | Actions |
|---|---|---|
| Database appears to not accept connections | Problems with database user credentials, problems with the connection string, connection limits reached | Inspect database server logs to determine cause |
| Network communications seem impaired | VPC and firewall issues, latency and timeouts between the application and database | Check firewall rules, looks for latency and timeouts, check for exhausted connection limits |
| Database server or application server is crashing | Potential data volume issues causing database server and app server to reach resource limits | Look for large amounts of returned data, optimize queries, add indexes |
| Database server is up but app is not displaying data | Potential recent changes to code including schema changes, unapplied migrations, malformed queries | Inspect source control history to look for recent changes and revert if necessary |
The best time to read this article is long before your database goes down. If your database is already down, the second-best time is now.
Database connection issues
Clues from application logs
If your database appears to be down, your application logs might give you insight into any problems accepting requests or connecting to the database. Because the application server handles both client requests and requests to the database, it usually logs errors if there are problems with the database.
If you are using Prisma Client, you can configure logging to control how logs are generated.
Is the application server handling connections successfully?
An application server which exposes an API and serves request by querying the database has two kinds of connections:
- User requests to the API exposed by the application server
- Application server requests to the database
When debugging an outage, keep in mind that problems with both kinds of connections can cause the outage.
Application server frameworks usually come with a built-in logger. It's common practice to log that the server can accept connections once the server has started.
For example, take a look at this log line:
The log shows that the server started and accepts connections at port 8000. But it's not enough to determine if an error occurred since the server started.
The next step would be to look at the most recent logs and check the HTTP status code of the most recent requests to the server. Typically request logs will look as follows:
Each incoming request log contains a timestamp, the URL, and other information about the request. The first log indicates a request coming in, while the second shows that the request succeeded with the HTTP status code 200.
Were there any database errors recently?
Since you're trying to debug a problem relating to the database, you should specifically look for failed requests. You can find these by filtering for requests with a response status code of 5xx, e.g., 500, that indicates a server error.
If you notice multiple requests with the 500 status code, look for the point at which these started and check for any other logged errors.
If the database is down or the database's credentials are wrong, you can see that logged. For example:
The log above indicates that your application server can't reach the database. In such cases, check the database URL in your application server.
If you are using Prisma Client, the error code reference can help diagnose what errors mean and how to fix them.
Database problems troubleshooting
Now that you know that your application server is running but cannot reach the database, the next step would be to determine why. It's best to approach this by eliminating potential sources of the problem.
If you're using a managed service for your database, check your cloud provider's status page first. Most cloud providers provide a way to check if their infrastructure is operational, e.g. Digital Ocean, Google Cloud Platform, and AWS.
Once you've ruled out any problems with the cloud platform, the next thing to check is the logs or status of your database instance.
Managed database logs
If the managed database provider you are using appears to be operational, your next step would be to check the logs for your specific database instance.
Most cloud platforms provide a way to view database logs in addition to some metrics such as throughput and query statistics. The layout and level of detail for logs differ from one cloud provider to the next. However, most cloud providers offer a sufficient level of detail to help you search for problems.
Each cloud provider also has a different way to access the database logs. Most make the logs easily accessible from the deployment management page.
For example, DigitalOcean provides a tab called "Logs & Queries" accessible directly from the deployment management menu.
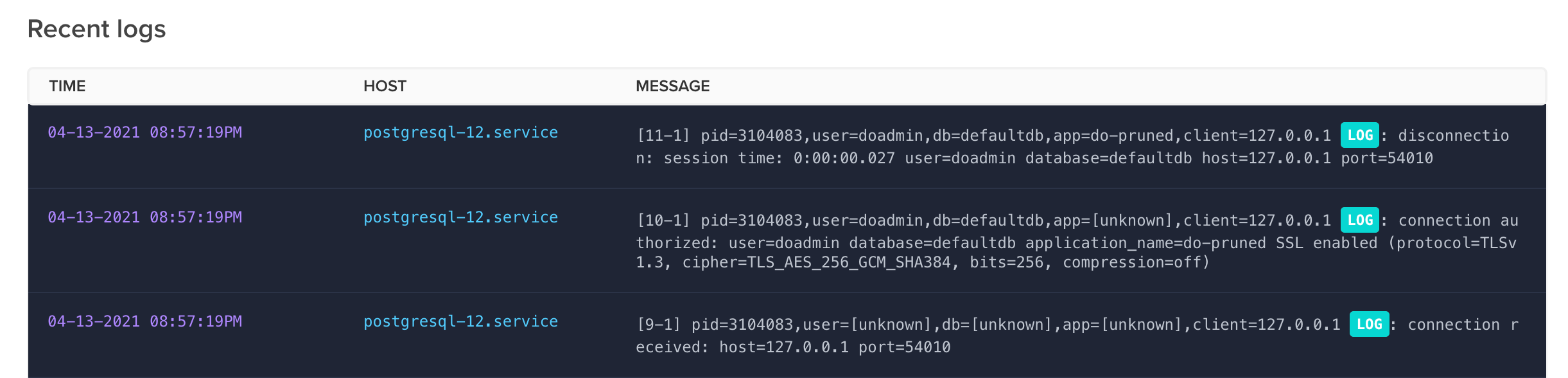
This section contains several different kinds of logging information, including a general "Recent Logs" section. You may find indications of issues connecting to the database or other problems that might be occurring.
Networking issues
Network-related issues can cause your database to be unavailable or seem to be down. In a three-tier application consisting of the client tier, the application tier (the back end), and the data tier (the database), networking issues can arise between the three tiers.
Networking related issues include:
- VPC and firewall policy issues
- Latency and timeouts between the application and database
When your database appears to be down or unresponsive, and you suspect that this might be related to network problems, it's best first to determine whether traffic is blocked to firewall policies or there are actual network problems.
Note: The recommendations below are based on assumptions that might not apply to your architecture. Hence it's recommended to understand the failure modes and their causes when debugging issues with your database.
VPCs
When provisioning cloud resources such as databases on cloud platforms, they are isolated within a virtual private cloud (VPC). In practical terms, the VPC serves as a private network for your application resources and is isolated from the public internet. If your database and application are not in the same VPC (or the same cloud), you typically need to configure the VPC's firewall rules to allow the application's IP access to the database.
Firewall rules
When you deploy your application and database to different cloud platforms or different VPCs, you need to configure the firewall to allow access from the application to the database.
While some firewall policies use black hole policies to silently drop traffic that is not allowed, others send a rejected response which can help you determine if the firewall is responsible for the disrupted connection. Likewise, if you have a "no route to host" type error, that can mean either that a network segment is down or that the routing logic is incorrect.
Moreover, If your application's IP is dynamic, it can change at any time. When the application's IP changes, it might fail to connect to the database until the firewall has been updated to allow the new IP access.
Firewall rules remedies
It's generally better to deploy the application and database in the same VPC and the same region so that the two communicate over a private network. It also prevents bottlenecks that public networks might incur. However, if that isn't possible, there are several possible fixes.
The first approach would be to use a dedicated IP for your application and add a firewall rule allowing access from the IP. This approach ensures that you don't need to update the firewall rules because the IP remains the same.
If using a dedicated IP is not feasible due to cloud platform limitations or the deployment approach, e.g., serverless, consider enabling access to the database via public networks. While this approach decreases the database's security, it ensures that your application won't experience any sudden downtime until you update firewall rules when your application's IP changes. Moreover, your database's authentication mechanism remains the main line of defense.
Please note that opening up connections to your database from the public internet is not recommended. Where possible, we recommend limiting connections to a specific IP address or using techniques such as VPC peering.
Latency and timeouts
When the geographical and network distance between the application and database is substantial, increased request latency and timeout errors can be a problem. In such scenarios, increasing the database connection timeout in your application might be necessary to avoid timeout errors.
ORMs and query builders hold a pool of connections to the database. These connections usually have a connection timeout configuration that controls how long to wait before timing out when establishing a connection.
It's recommended to set an initial baseline timeout value and load test the application to see how it performs. Based on the number of failed requests from the load test, you might want to adjust the timeout and try again until you're confident that timeouts are not the cause of the problem. If your connection timeout configuration is too low, you run the risk of these timeouts leading to failed requests.
Exhausted connection limit
Another common challenge with connection-based databases like MySQL and PostgreSQL is that you can quickly exhaust the database's connection limit. Connection-oriented databases impose a limit on the number of open connections to the database.
When you deploy your application using the traditional long-running process model, you can multiplex many incoming requests on fewer DB connections in a pool. For example, a single server instance might handle 100 concurrent HTTP requests with a pool of 20 DB connections.
On serverless functions, however, each function instance can only handle 1 HTTP request at a time. Because each incoming request requires at least one connection to the database, there is no way for you to multiplex database connections.
Given this, it's recommended to use the database connection limit and then distribute those between the server instances that connect to it in a way that doesn't exhaust the database's connection limit. For example, suppose your database has a connection limit of 20. If you have two instances of your application server, you would want to set each server instance's connection pool to a maximum of 10 connections.
For serverless deployments, consider running an external connection pooler like PgBouncer – an additional infrastructure component that holds connections to the database and multiplexes incoming database queries from the serverless functions.
Data volume issues
As an application grows, the data volume for that app will most likely grow as well. A key consideration for both performance and database uptime is the volume of data being processed to furnish a given request. Inefficient queries written for the app when the total data volume is small can turn into bottlenecks that can tank performance and cause outages when that data grows.
Large data volumes can have an impact at three locations:
- The database server
- The app server
- The client
The database server
When a database query is made from the app server, the database server's responsibility is to retrieve the requested data and send it back to the app server. In doing so, the database server must first scan the retrieved data into its own memory. When data volumes are small, the process of scanning data into memory and forwarding it to the app server is trivial. However, if a very large amount of data is returned from the query, an underprovisioned database server can crumble under the load.
This scenario often arises when queries that were initially sufficient with a small total database size are not adequately optimized as the data size grows.
Consider a scenario where an application needs to display a list of contacts for a user. A typical database query to furnish this data likely selects data scoped to that user.
Depending on the needs of the application, the app server may not have anything further to do than to forward the results to the client. This query is unlikely to cause data volume problems.
However, consider what would happen if there was no WHERE clause in the above query.
If instead, the query asked for all contacts in the database and the app server was then responsible for filtering the list based on userId before forwarding the results to the client, the difference in data volume could be astronomical.
With relatively small overall data volumes, this inadequate query might go undetected. As data volumes grow, performance degradations might become noticeable but might not totally break the application. As this happens, however, the database server will be loaded beyond what it may be provisioned for. As data volumes continue to grow even further, a tipping point may be reached where the database server is no longer able to handle the load.
The app server
Much like the database server does not have unlimited capacity to process large volumes of data, the same is true for the app server. It's possible that you have more control over capacity and sizing for your app server than you do for your database server, but increasing capacity on the app server may be unnecessary.
A large volume of data returned from the database server takes time and resources to process on the app server. If the app server is responding to a request from a client application, long waits at the app server can be problematic. Many cloud hosting providers enforce a request timeout after several minutes have passed. Web browsers will automatically retry requests after several minutes of a request sitting in a "pending" state, putting further strain on the system.
The client
Client applications might be most susceptible to bottlenecks caused by large data volumes. Unlike the app server and database server, where you may have the ability to increase capacity, client applications that run in the browser or on mobile devices are subject to limitations of the browser, operating system, or both.
Sending an inordinately large volume of data to a client application will cause delays in processing and can severely degrade responsiveness. Once a given data size has been reached, the browser may become completely unresponsive and ultimately crash.
If very large data volumes are forwarded all the way from the database to the client, performance degradations will be felt every step along the way. This trifecta will lead to long load times and possibly a perceived outage at any one of these points. Compounding the problem, troubleshooting where the bottleneck exists can become difficult.
Data size remedies
The fix for performance degradations and outages caused by data volume issues is nearly always to limit the amount of data returned from the database server. Doing so will alleviate problems at the database server, the app server, and the client.
Scope data with WHERE clauses
In the fictitious query example above, the entire contacts table for a database was queried. This means the database server needs to scan the whole table into memory before filtering down to the desired results, which can put tremendous load on the database server and app server.
Start by looking for queries that are casting too wide a net. Chances are that these queries are taking a long time to process at the database server. Looking at the logs for long-running queries can give indications of where this is happening. Instead of returning many results and then filtering through them with app code, construct your queries to return the subset of results that are truly needed. In SQL, use the WHERE clause to get specific about the data you actually require.
Paginate data with LIMIT and OFFSET
If large volumes of data are truly required for client applications, it's advisable to introduce pagination.
Pagination is a design pattern that limits the total number of records to be queried and returned at a given time. If a user would like to see more records, they must request them explicitly.
This design pattern is most often implemented using the LIMIT and OFFSET clauses. By choosing to skip a certain number of records and also limiting the number of returned results, the client and app servers can achieve a pagination experience.
The query for the first page might look like this:
The query for the second page would then just set the value of LIMIT to the OFFSET value to get the next "page".
Troubleshooting data volume issues
Most databases offer tools that can help troubleshoot data volume issues. In particular, many databases offer an EXPLAIN command, which will surface the execution plan for a query and offer insights into any associated problems.
For example, in PostgreSQL, the EXPLAIN command shows the query plan for the statements under consideration and will display estimated execution cost. This is an estimate of how long it will take the query to run.
This information can be helpful to narrow in on the specific tables or query statements that are causing bottlenecks.
In addition to manually calling the EXPLAIN command, many cloud database providers offer a way to automatically visualize the queries that are causing problems. This information is often found in the "Slow Queries" view for cloud providers. Check the Slow Queries section of your database provider to find which queries might be adversely impacting your application.
Adding indexes
Problems associated with large data volumes can often be remediated using indexes.
Indexes for a database table can be conceptualized in the same way as an index in a book. If you were looking for information on a specific topic in a book, it would take a long time to read through the entire book to find it. Instead, you can consult the index to look up the specific topic of interest. If it exists, it will point you to the specific pages that the topic is discussed in the book.
The same concept is applied to database indexes. Adding indexes to a database table based on common access patterns allows for fast lookups.
For example, if you have a database table of users that contains a column for email and that table is queried to look for users based on their email, it helps to improve performance to create an index for that table based on the email column. Without the index, the whole table will be scanned to find the user by their email address. If the table size is very large, this can create significant performance issues. If, however, an index is created for that column, lookups will be fast because searching for a specific email will immediately point to the exact row that is needed.
Adding indexes to a database requires planning and consideration and is something that should be done before your database causes outages in your application. However, if you can find a specific query or queries responsible for producing the outage, it can be helpful to add an index to alleviate the strain immediately.
Breaking code changes
A suspected database outage might be traced back to recent breaking changes made to client or server code. In these cases, it is likely not the database itself experiencing an outage, but rather the code used to retrieve data, process it, and return it to the client may have broken.
Code changes that might cause interruptions generally fall into three categories:
- Database queries
- Server code
- Client code
Database queries
Changes to database queries, even if they are small, can impact an application. If using raw SQL, a query statement might have become invalid in a recent code change. If the query itself is still valid, it might have been changed to return results that are no longer processable by other parts of the application.
Inspect source control changes to look for recent changes to database access (SQL statements or ORM usage). Try to isolate queries that are related to specific areas of the application that are impacted.
If there are no indications of changes to database access, another possibility is that the database schema has changed, but migrations have not been run. Look for any recent migrations that might still need to be applied to the production database.
Client and server code
Code changes to app code in the client or the server, even if small, can have the potential of creating what looks like a database outage. There are many specific issues that could be at the root of the problem, but some examples include:
- the client might be calling a server endpoint that no longer exists
- a server endpoint has changed the validation rules for payloads or query parameters
- the server is trying to access properties from returned data that has become invalid from a recent schema change
Conclusion
Database outages, regardless of the underlying cause, can be very stressful events. In the rush to try to get the application back up and running, it can be difficult to properly reason about where the database problems might be originating.
Every database outage is unique, and there's no one-size-fits-all solution when one occurs. However, being well-versed in possible problems and their associated solutions can help you determine the cause of the problem more efficiently and reduce the time it takes to getting back up and running.
As with most problem solving, it's best to become familiar with potential solutions to problems before they happen. We hope this guide helps you on your way to achieving just that.

Ryan Chenkie
Ryan is a full stack developer and is particularly interested in databases and APIs. He’s the founder of CourseLift, a course hosting platform that helps authors with marketing and sales.