PostgreSQL
How to configure a PostgreSQL database on RDS
CONTENT
- Introduction
- Why Amazon Web Service's RDS?
- Starting the database creation process
- Configuring standard PostgreSQL deployment options
- Choosing the DB instance class
- Configuring storage options
- Deciding on connectivity strategy
- Setting up database authentication
- Configuring backups, encryption, monitoring, and more
- Finishing up
- Conclusion
Introduction
Amazon Web Service's Relational Database Service (RDS) is a popular option for database hosting because of its flexibility and robust feature set. Development teams can provision new databases for personal use, staging environments, and production workloads and integrate them seamlessly with the rest of AWS's product suite.
In this guide, we'll discuss how to use Amazon's RDS to configure a production-capable PostgreSQL database. We will walk through important options in the creation process, discuss trade-offs, and configure a reliable, robust database setup designed for early production deployments.
Why Amazon Web Service's RDS?
Before we get started, let's talk briefly about why AWS's Relational Database Service can be a good fit for many teams.
RDS as a service was first released in 2009 as a configurable, managed service for MySQL databases. PostgreSQL support was added in 2013, giving the platform ample time to stabilize and mature as new features were released and additional use-cases accounted for.
Some of the core features that make RDS an attractive option include:
- Deployment into separate physical locations (Multi-Availability Zones): create active or standby replicas in physically distinct data centers to increase availability and reliability in the event of location-based outages
- Integration with AWS IAM security model: leverage existing access controls and identity features to configure authentication, authorization, and role-based access policies between databases and client applications.
- Configurable backups, encryption, and monitoring: use platform-integrated backups, observability tools, and encryption to shrink and centralized the operational costs of maintaining databases.
- Costs based on usage: costs are tied directly to the features and usage of the database, alleviating uncertainty over long-term capacity planning.
With these benefits in mind, let's get started setting up a PostgreSQL database instance to walk through the process.
Starting the database creation process
To begin, log into your Amazon Web Services console using your AWS credentials. If you have not yet signed up for AWS, you can do so now by following their sign up process.
From the AWS console home, type rds in the service search bar to locate the RDS service:
Click RDS under Services to go to the main Amazon RDS page:
Scroll down until you can see the Create database section and click Create database:
You will be taken to the database creation page where you can select your desired configuration.
We will be spending the rest of the guide covering the different options available and offering suggestions for production-capable configurations.
Configuring standard PostgreSQL deployment options
The first part of RDS creation process determines how you want configure your database as well as the basic properties of your new database like your database engine, deployment type, and basic configuration. Let's get started.
Configuring the creation method
The first step in provisioning a new database on RDS is to choose the creation method:
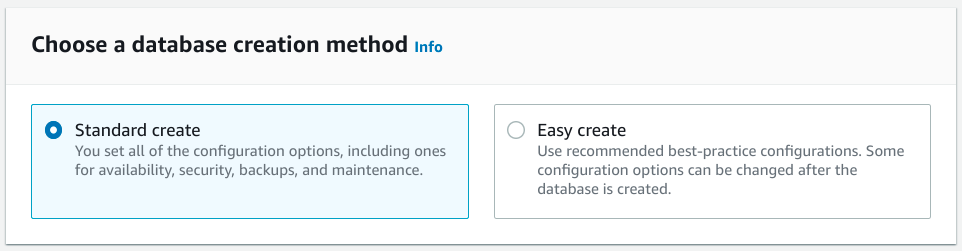
While the Easy create method can help you choose some reasonable defaults, it doesn't provide the level of flexibility that you probably want when configuring an important database for your environment. The Standard create option offers additional options and is still a relatively short process.
Choose the Standard create so that you have full control over the creation process.
Selecting the PostgreSQL engine and version
Next, choose the Database Engine:

For this guide, we will be configuring a PostgreSQL database, so we will choose the PostgreSQL option. Amazon's Aurora is an alternative PostgreSQL-compatible option that provides Amazon's own scaling and management features. For this guide, however, we will focus on a PostgreSQL native deployment.
Choose the version of PostgreSQL that you wish to use. The default selected version is typically a safe choice, but you may also want to select the latest release for newer features or an older release depending on compatibility with your application libraries.
Choosing the production template
Next, you will be asked to choose a Template:
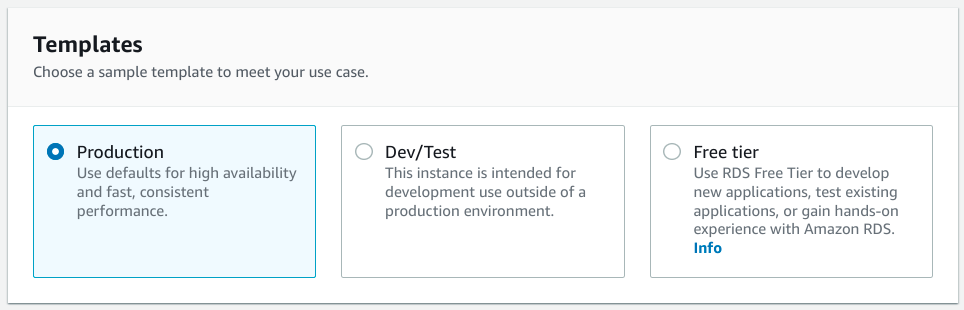
Templates are meant to provide preselected options that match typical deployment scenarios. Since we are provisioning a production database, select the Production template.
Setting the database availability
The next section includes the first major decision you'll need to make in regards to your deployment: the database's availability and durability:
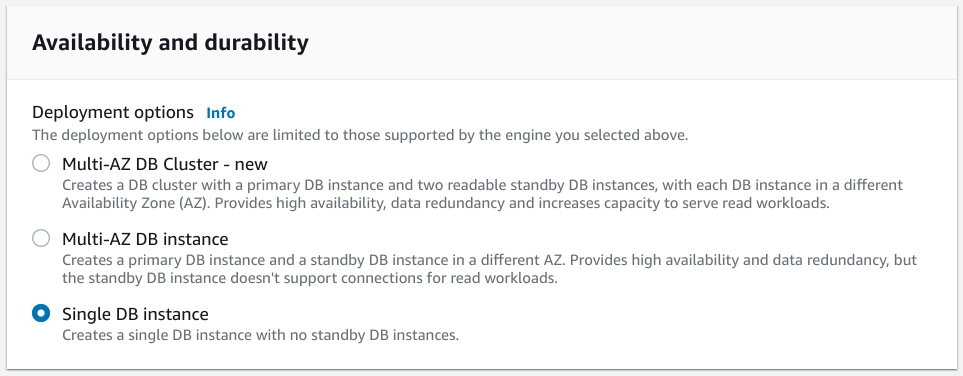
This section determines exactly how your database will be deployed within AWS's environment. This has implications on how resistant your setup is to failure and outages, both of your specific instance and of regional disruptions in Amazon's infrastructure.
Let's take a look at the various options we have, what they provide, and what scenarios they are useful for. For this guide, we will be recommending a Single DB instance, so feel free to skip ahead if you aren't interested in the other options.
Multi-AZ DB Cluster
The safest, most robust, and most expensive option is the Multi-AZ DB Cluster.
This configures a PostgreSQL cluster consisting of a primary DB instance along with two read-only standby replicas, each deployed to different physical locations. This option helps prevent outages of your database in the event of failures while increasing your available read throughput through the replicas.
With that being said, this option also is very costly as you will have to pay for three separate database instances deployed to the different availability zones.
This may be a good option if your database downtime equates directly to significant loss of revenue. The increase in read IO is also noteworthy if your typical database usage patterns are very read-heavy. If this matches your use-case, you may also want to consider evaluating Amazon Aurora for a similar level of availability that might be less costly in the end.
Multi-AZ DB instance
This option deploys your database as an active primary instance along with a standby replica in a different availability zone. The standby replica will be kept up-to-date so that, in the event of a disruption with the primary instance, a failover can trigger and the standby can assume the responsibilities of the primary.
In contrast to the Multi-AZ DB Cluster discussed above, a Multi-AZ DB instance only has a single standby replica. Furthermore, the standby replica can only be used for its standby capacity. It does not support read-only workloads.
This options can be a good choice if you want some availability protections without a need for greater read throughput. You will have to account for the cost of two database instances, so the price will higher than a single instance. If downtime is extremely expensive for your operation, you this might be a good option to prevent lapses in availability in the event of an outage.
Single DB instance
A single DB instance is a standard deployment of a single database within one availability zone. This provides no additional availability, meaning that your database's availability is directly tied to the uptime of the database instance. If it has a problem, your database and all of the data it manages will be inaccessible until service is restored.
With that in mind, this option is also the least expensive. The deployment consists of a single instance so there are no additional resources being deployed that you will be charged for.
This option is associated with some level of risk, but for many use cases, the risk is acceptable and the cost of alleviating it is too high. Amazon RDS has a good track record for reliability, even within a single AZ, so for many use cases, the chance of a short period of downtime is acceptable.
For this guide, we will be choosing a single DB instance because it is often sufficient for production deployments that aren't extremely sensitive to downtime. However, if your revenue and reputation are strongly associated with your database's uptime, it might be wise to consider a different choice.
Configuring the basic settings
The next section allows you to configure your deployment's basic settings:
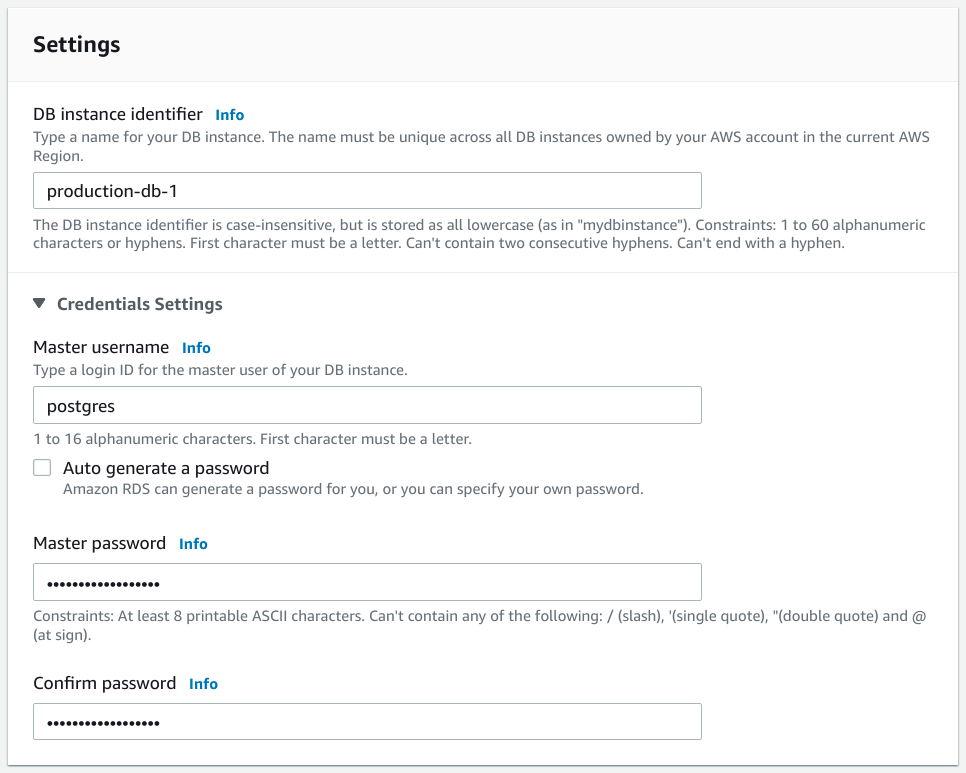
First, you have the opportunity to name your database instance by setting the DB instance identifier. Select something unique that will help you understand the role and purpose of the database when displayed within the AWS console.
Next, configure the credentials for your database instance. Start by setting the master username for your PostgreSQL database. By default, most PostgreSQL client tools assume that the master user is called postgres, so you can keep that username if appropriate.
Note: The master username is the main administrative account within the PostgreSQL database instance. You should always create and configure additional application-specific usernames with limited privileges after provisioning your database instance. Configure your database clients and applications to use those less privileged identities for their daily operations. Only use the master username for your initial configuration and to create more limited and narrowly scoped avenues of access.
You then have the option to set and confirm a password for the master username. You can either choose a strong, preferably machine-generated, password for the account or you can check the Auto generate a password box to have AWS automatically generate a secure password for you.
If you select your own password, save your password somewhere secure as you will be unable to retrieve it later. Likewise, if you auto generate a password, you will only have access to the password the first time you access the credentials in the AWS console after creation. Be sure to record the password securely as you won't be able to retrieve it again at a later time.
Choosing the DB instance class
The next major decision you'll need to make is your DB instance class:
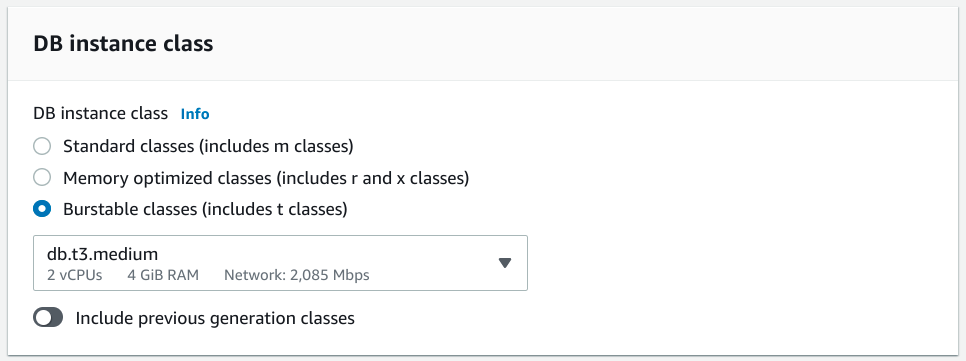
Essentially, the instance class of your database dictates the size of virtual machine your database will be deployed to and the resources available to it. You have a few different options for the type of instance you want to choose as well as combination of resources within each type.
The three major categories of instance classes are:
- Standard: These include "m" classes that you may be familiar with from AWS's EC2 (Elastic Compute Cloud) instances. Basically, these are well balanced, general purpose instances designed to have a reasonable ratio of CPU to memory.
- Memory optimized: These include EC2 "r" and "x" instance classes. The instances in this category have a higher ratio of memory to CPU that is useful for database operations that involve loading large datasets into memory at once.
- Burstable: These instances are generally a bit lower performance than the others but can still occupy a sweet spot for many applications. They offer a lower baseline CPU performance but allow bursts of higher performance to accommodate spikes. This allows you to pay for lower average usage while still being able to handle additional workloads from time-to-time.
The instance class you choose as well as the specific arrangement of resources you need are highly dependent on your applications' usage patterns. However, there is some general guidance we can provide to help you make your selection. Keep in mind that you can always scale your database at a later time if your needs change.
General suggestions for choosing DB instance classes
In general, RAM tends to be a more important factor than CPU with most relational database workloads. Because of this, you shouldn't necessarily discount the burstable classes out of fear of low performance. They offer some of the best value while still being able to reasonable performance.
Specifically, instances like the db.t3.medium, which provides 2 vCPUs and 4 GiB RAM, is a good baseline selection for many use cases if you are just starting out. The CPU should be able to handle a medium level of activity while accommodating request spikes. Assuming the hardware performance is suitable for your project, one of the first limitations you might run into is the network cap of 2,086 Mbps, so keep that in mind as you decide.
If you want a higher level of CPU performance for a standard database with a decent amount of traffic, you may want to consider a standard class instance with 2-4 vCPUs and 8-16 GiB of RAM. The m6g instances are advertised at having up to a 40% better price-to-performance ratio than the older m5 instances, so they are often the better choice when looking at standard instances. With that in mind, the db.m6g.large and db.m6g.xlarge instances are good starting selections for this instance class type.
Memory optimized database instances are primarily useful if you know that you will have to load large data sets into memory. This might be because your tables hold many records or because you frequently query large numbers columns. If you make heavy use of PostgreSQL's JSON columns, this might be something to consider. That being said, it's often better to start with a more standard configuration and change the instance class if you find those resources are not sufficient.
Configuring storage options
Next, you'll need to configure the storage for your database instance:
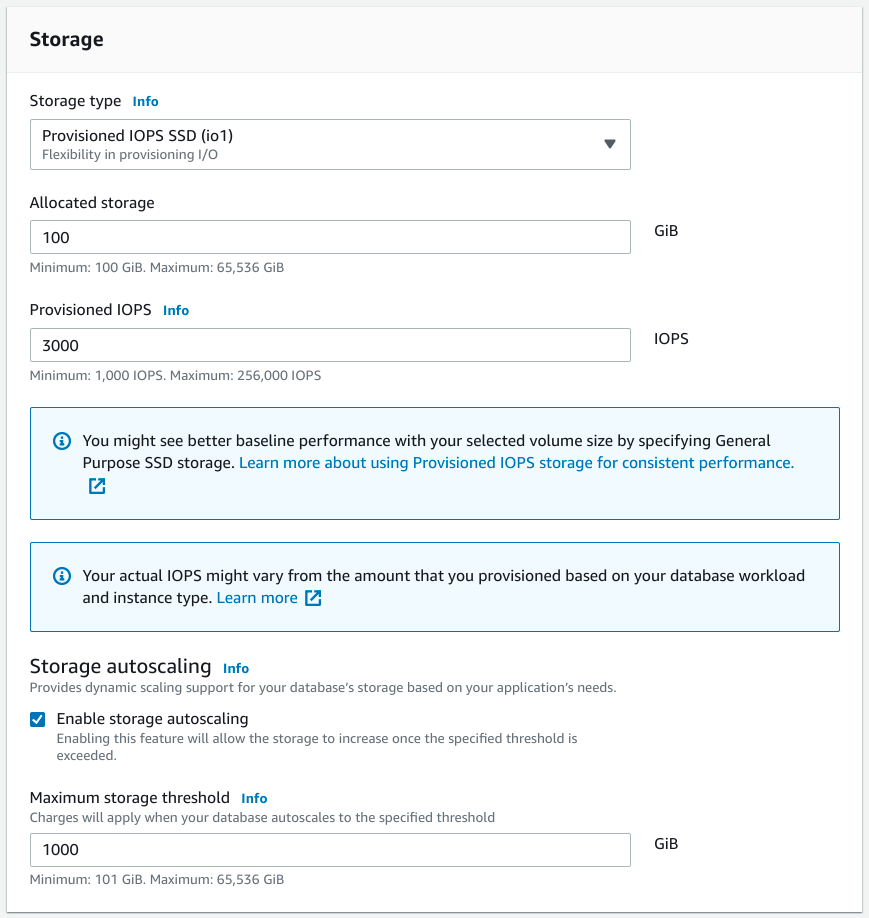
Choosing the storage type
RDS offers three different types of storage that are appropriate for different scenarios:
- General Purpose SSD (gp2): This is a standard solid-state drive selection. Your IOPS (input/output operations per second) available for your storage device is tied directly to the size of space you allocate. The baseline IOPS is set at 3 IOPS/GiB allocated, with the ability to burst to 3,000 IOPS for short periods of time.
- Provisioned IOPS SSD (io1): This option allows you to decouple the amount of storage space from the IOPS allocated to your database.
- Magnetic: Magnetic storage uses traditional spinning disks instead of SSDs.
In general, it is almost always best to start with the general purpose SSD option. This allows you to set the amount of space that you need and deploy your database on SSDs. The magnetic option is rarely a good choice as it has slower speed and is limited to 1000 IOPS.
The provisioned IOPS SSDs are a good choice if you have performed fairly robust application profiling and have a good idea of the amount of IOPS your environment generates with various workloads. This also tends to be a lower number than anticipated due to caching and other mechanisms that can lower the amount of operations that actually hit the drive. Generally, think of this as an advanced choice that might become appropriate once you have experience running your exact configuration over time.
Selecting the initial storage space
After selecting your storage type, choose the amount of storage to allocate. This is also highly dependent on your application. In general, however, people tend to overestimate the amount of space they'll need at the beginning. Start low and remember that you can always scale up.
Configure autoscaling
Next, select whether to enable autoscaling. This option allows your storage space to automatically scale with usage. This is generally a good idea as it allows you to start with a smaller initial allocation for a more affordable price and then automatically increase the storage space as your data increases. You can configure a maximum scaling amount to make sure that you end up scaling more than you're comfortable with.
In general, it is often enough to start with anywhere from 20 to 100 GiB as your initial allocation (often depending on what provides you with enough IOPS) and then set your maximum storage threshold to the maximum size you are willing to pay for.
Deciding on connectivity strategy
After configuring your storage, the next major decision you'll have to make is in regards to your database's connectivity:
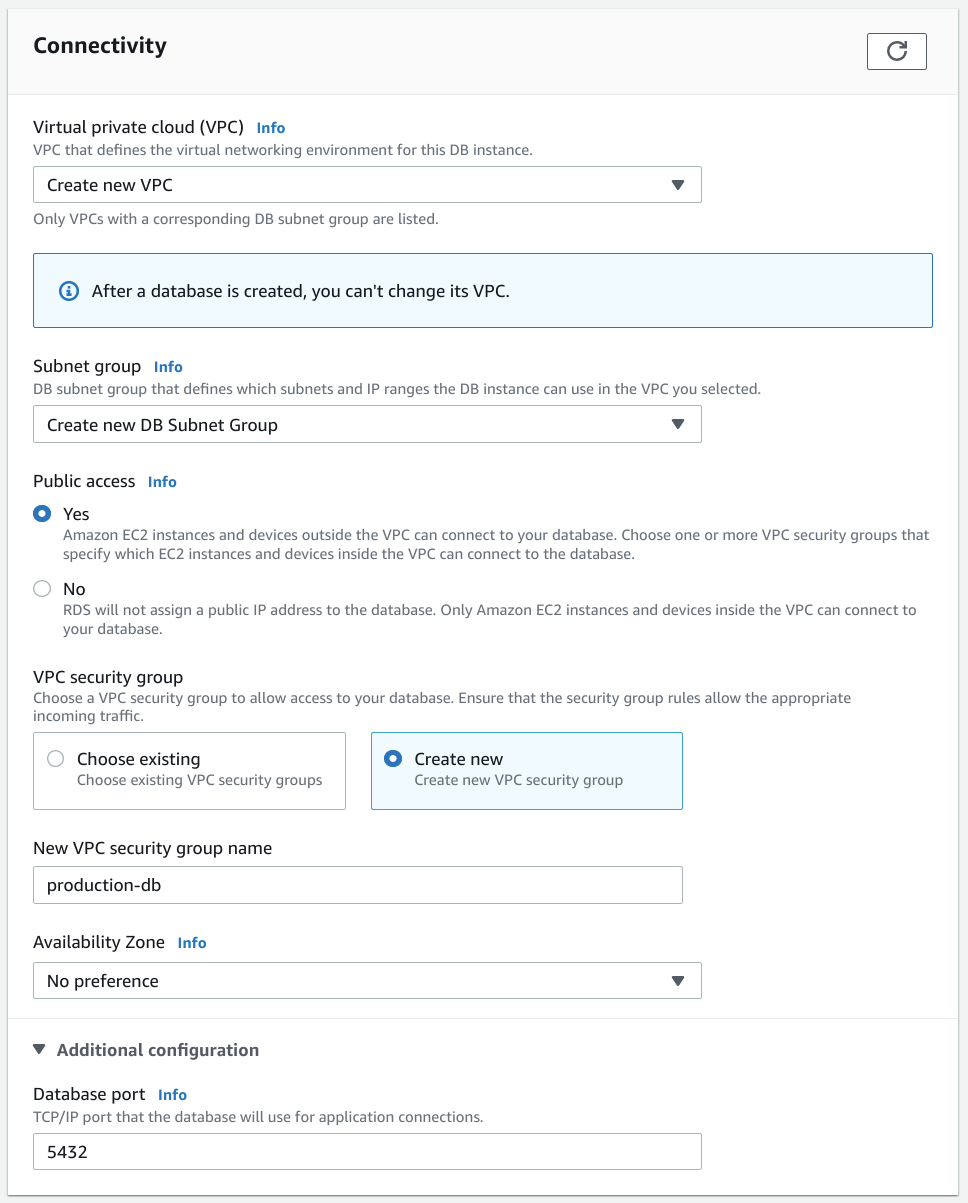
This section includes a number of different options that can be confusing if you aren't intimately familiar with AWS's security and networking models.
The general strategy we'll recommend here for a production-appropriate deployment is to create new instances of each available option instead of reusing existing options. You might have to adjust this strategy if you are deploying your database into an existing environment where your applications are already running, but the general rule offers the most isolated and secure approach for new deployments.
Configuring the VPC
When asked to select the Virtual Private Cloud (VPC) where your database will be deployed, it is usually a good idea to deploy it to a new VPC or the VPC containing applications that will access it. Deploying to the default VPC is usually not recommended as it means that your database will be subject to any adjustments you make to the default network environment.
Choosing the Subnet group
Next, you need to select the Subnet group. This defines the IP range within the VPC where your database may be deployed. Generally, it's a good idea to create a new group here as well.
Deciding whether to allow public access
One of the most important choices you'll have to make is whether to allow public access to your database instance. This is largely a function of your security requirements and your ability to configure special access to your database.
The most secure approach is to turn off public access. This will only allow your database to be accessed by (or through) instances deployed within the same network environment as your database. To access your database externally, you'll need to configure a jump host or an internet gateway with external access to authenticate and route external connections to your database. This can be a significant undertaking if you're not familiar with configuring infrastructure or managing network rules.
The other approach is to allow for public access. This will make your database instance accessible from the public internet. It is less secure as anyone can attempt to connect to your database, but it does allow for a simpler access model from external connections. If you choose this option, ensure that all of your database passwords are very strong and rotated frequently. You will likely see external attempts to access your service in the logs, so password strength is vitally important.
The choice of whether to enable public access or not is more complicated than it initially appears. If you enable public access, you can still lock down access to a specific set of external IP addresses and provide other points of configuration to filter out illegitimate connection attempts. In general, it is best to go with the most secure configuration you'll be likely able to support over the long term.
Choosing the VPC security group
VPC security groups control the access rules used to connect to the instances deployed within. These are basically firewall-like access control policies that help limit the types of connections that can be made to your database instances.
Create a new VPC security group unless you have already configured one for production-database purposes. Choose a name that will help you remember the focus and role of the security group when displayed in the AWS console.
Choose the availability zone and port
You can choose the availability zone within your current region where you want to deploy your database instance to. If you have no preference, feel free to leave "No preference" selected.
If you open the "Additional configuration" options, you can optionally change the port where PostgreSQL will listen. Changing this can help alleviate some level of chatter in the connection logs of an open instance, but it does not offer any significant security improvements and can make connecting more tedious.
Setting up database authentication
Next, you'll need to choose the type of authentication you want to use for your database instance:
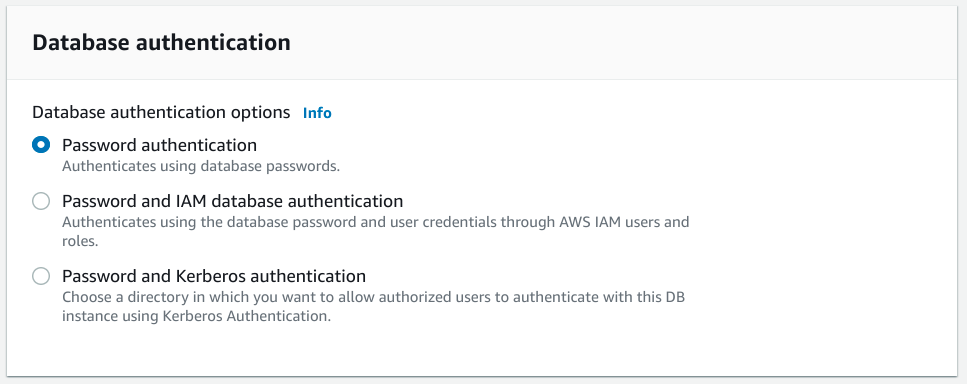
The choices are:
- Password authentication: Standard password authentication using PostgreSQL's native capabilities.
- Password and IAM database authentication: Use both PostgreSQL's native password capabilities as well as AWS IAM roles to authenticate. As an alternative to using database passwords, you have the option to authenticate to your database instance using IAM authentication tokens.
- Password and Kerberos authentication: Use both PostgreSQL's native password capabilities as well as an AWS Managed Microsoft Active Directory instance created using AWS Directory Service. This allows you to use Kerberos-style authentication through tickets if your organization already uses an AWS managed AD instance.
In general, it is reasonable to just use password authentication unless you have a need for more complex configuration. The IAM database option may be attractive if you are heavily invested in the AWS ecosystem and IAM-based authentication for many other parts of your infrastructure. It is not worth choosing the Kerberos option unless you are already using that service for other purposes.
Configuring backups, encryption, monitoring, and more
If you expand the Additional configuration section, you have the opportunity to configure some additional options. We'll cover those in this section.
Database options
The first additional section allows you to configure some additional options for PostgreSQL:
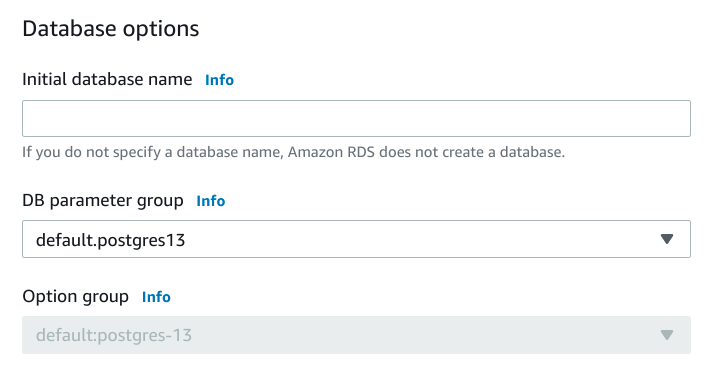
If you'd like, you can choose to have RDS automatically create an initial database for your deployment. This is usually unnecessary as any migrations you run or other setup scripts you might have typically create the necessary database structures within the instance.
You can also sometimes choose a DB parameter group for your instance. Multiple selections here might not be available depending on the selections you made earlier and whether you've configured parameter groups outside of the creation process. When present, they allow you to alter the PostgreSQL parameters applied to this instance.
PostgreSQL does not support option groups, so that drop down will not be active.
Backup
Next you can configure the options associated with automatic database backups:

If you want to enable automatic backups, select the enable automatic backups box. This will tell AWS to automatically take daily point-in-time snapshots of your database instances that you can use to restore from. It is worth noting that, while not mentioned on this page, backups will be stored in AWS's Simple Storage Service (S3) and that you will be charged for the space they consume.
By default, backups are set with a retention window of 7 days, meaning that you will be able to restore snapshots of your database taken within the last 7 days. If you are using this feature, you might want to increase the retention period to 14 days to give yourself more time to catch unwanted changes. Keep in mind however that increasing the retention period will incur greater costs for the additional storage.
If you have any preferences around when backups occur, you can select an appropriate window of time, otherwise, it's safe to leave as "No preference".
Keep "Copy tags to snapshots" selected to make it easier to find the appropriate snapshots within S3.
If you want additional protection, you can also select Backup replication to replicate your changes to a different AWS region automatically as well. This will allow you to quickly restore from a different region, but will increase your S3 storage costs and data transfer costs.
Encryption
Next, you can configure the on-disk encryption for your database instance:
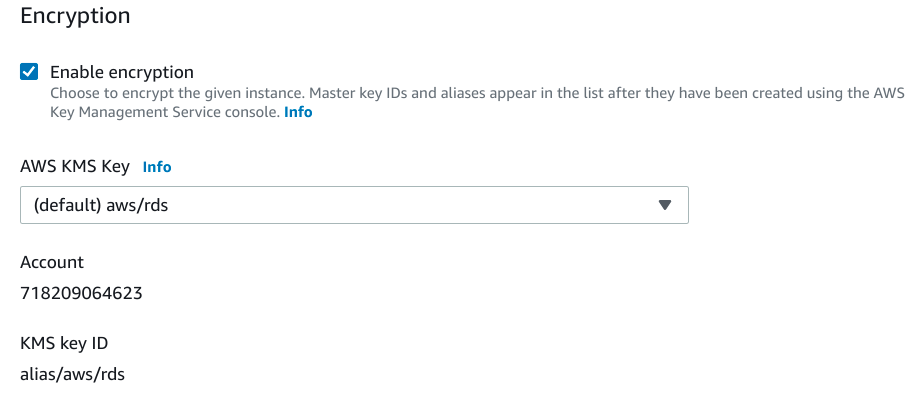
It is almost always a good idea to enable encryption for your instance for additional security.
In general, you can use the default AWS KMS Key for this unless you have additional requirements such as encrypting to a key used by a different AWS account.
Performance insights
Next, configure the performance insights for your instance:
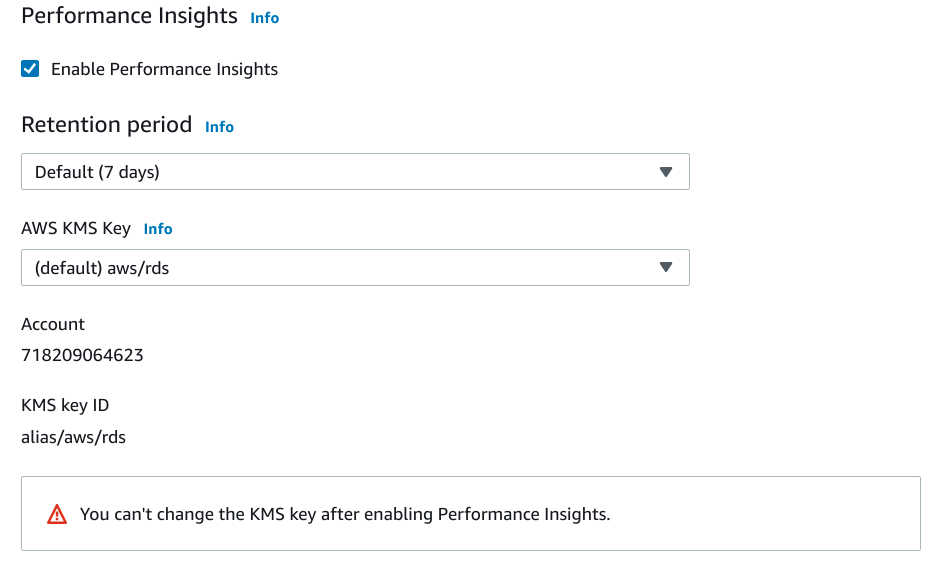
Performance insights are a feature that helps you debug performance issues in your RDS instances. By default, the insight data will be retained for 7 days for free. You can alternatively choose long term storage of 2 years for an additional cost depending on your CPU instance types.
Again, you can leave the default AWS KMS Key selected for this encryption unless you have special requirements.
Monitoring and Logs
Next, you can configure the monitoring and logs for the database:
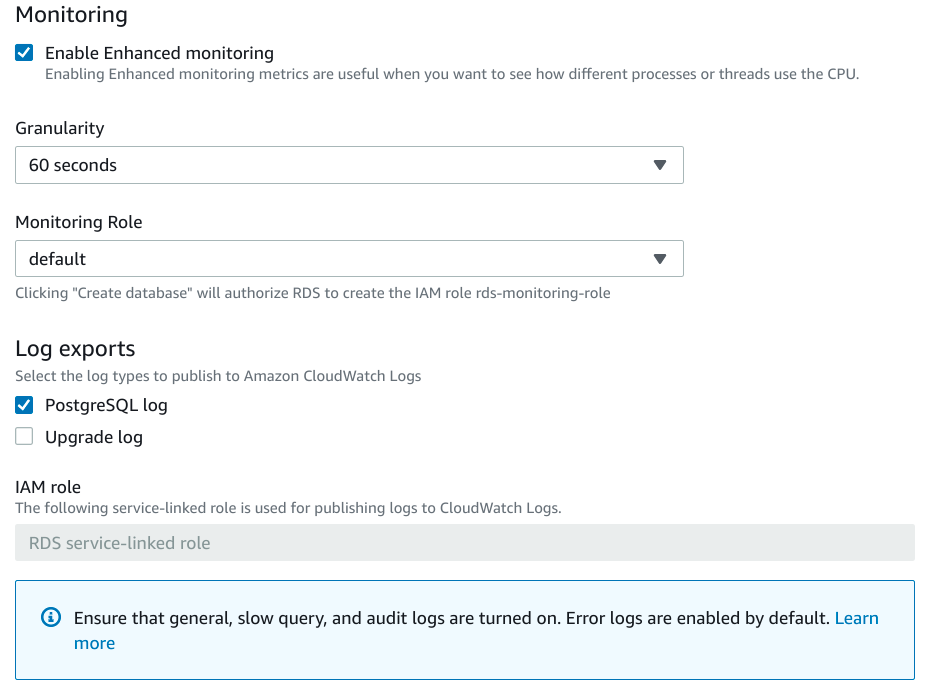
In general, it is helpful to enable monitoring to give you better visibility into your database instance and how it is performing.
As for exporting logs, it is typically safe to disable this by default unless you need it. Your application logs will usually bubble up database-specific information as needed, but you can always enable PostgreSQL log exporting if you find it helpful. Logs will be exported to AWS CloudWatch Logs.
Maintenance and deletion protection
The maintenance and deletion protection sections finish off the additional configuration:
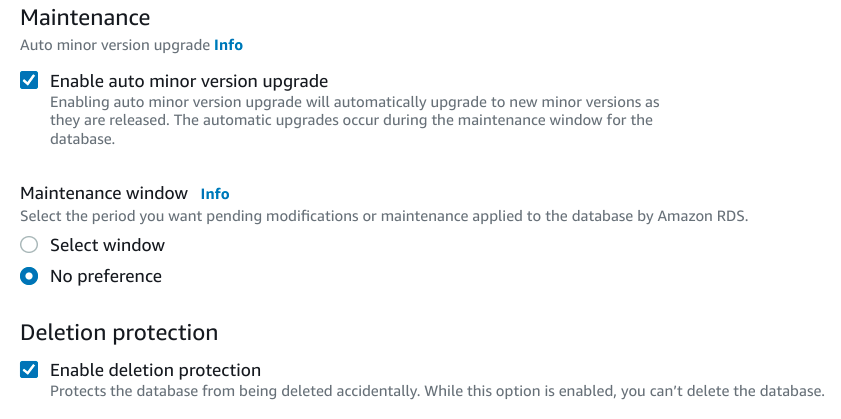
It is typically considered safe to automatically upgrade minor versions of PostgreSQL automatically. Minor versions should have no breaking changes and upgrades should be performed relatively seamlessly. Select an upgrade window if you have a preference.
It is always a good idea to enable deletion protection for your production database. This prevents you from accidentally deleting your database instance by requiring you to revert this option before a deletion will be successfully processed. There is no reasonable reason to opt out of this option for most use cases.
Finishing up
We've finally reached the end of the configuration process. At the bottom of the page, you can see an estimate for the monthly cost of your configured database instance:
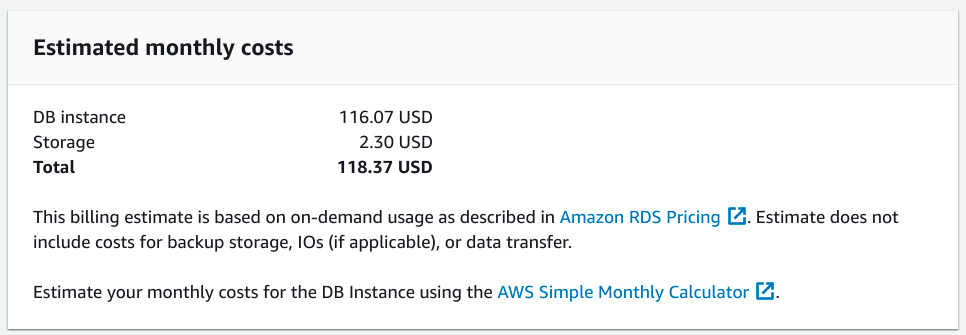
Take special note of the text beneath the estimate that reiterates that the cost calculation displayed does not include the cost of backup storage, IO, or data transfer. These additional costs can be substantial if not accounted for and limited, so ensure that you are comfortable with the idea of additional charges before proceeding.
When you are ready, click Create Database at the bottom of the page:

Your database instance will be provisioned according to your configuration. This may take a few minutes to complete depending on the size of the instance you selected and the options you enabled.
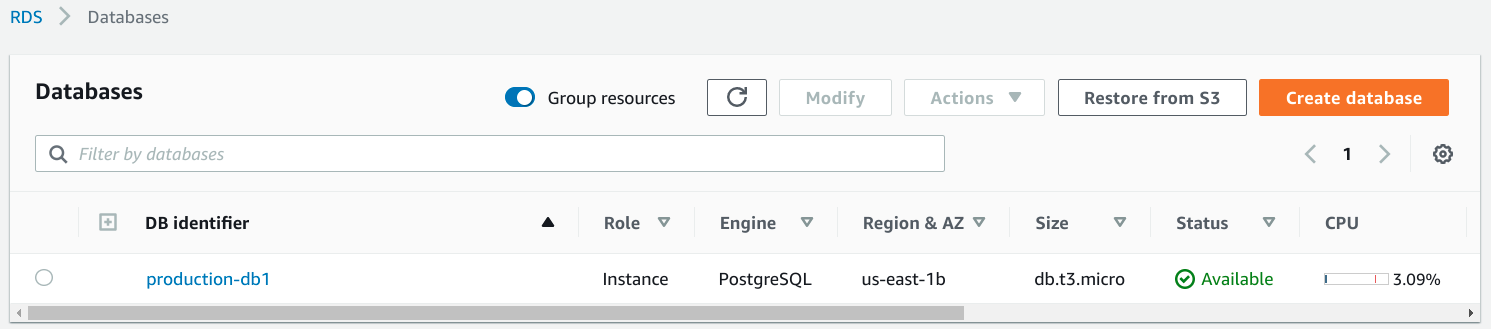
When your instance is ready, it will be displayed in the Databases section of the RDS dashboard:
Viewing auto generated password
If you configured AWS to auto generate a password, you will see a notice like this at the top of the screen:

Click View credential details to get see the password:
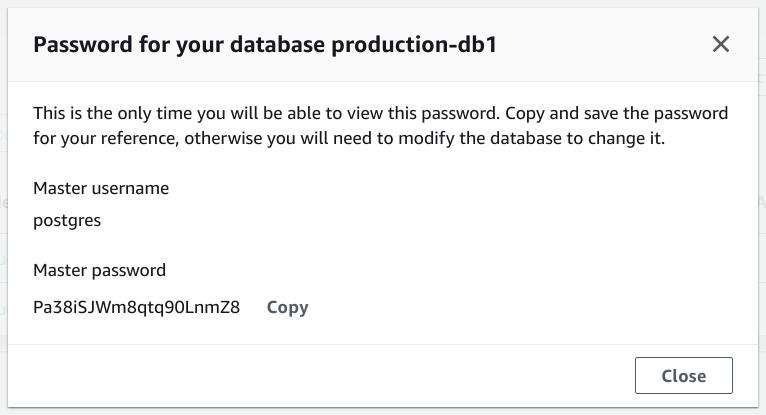
Note that this is the only time you'll have access to this password and you'll have to regenerate it if you lose it.
Viewing other connection information
For the rest of the connection information, click on the instance name.
In the Connectivity & security tab, you can find your database's endpoint and port number on the left-hand side:
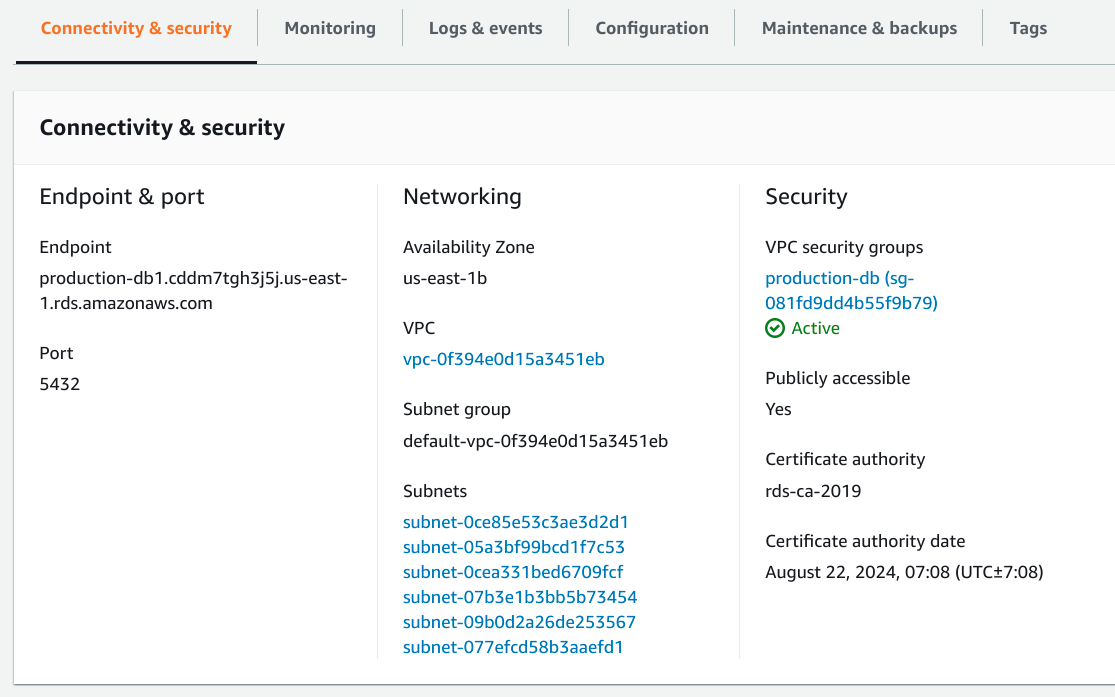
In this example, our endpoint name (URL for the host) is production-db1.cddm7tgh3j5j.us-east-1.rds.amazonaws.com and our database is listening on PostgreSQL's standard port: 5432.
To find the master username that you configured (this will be postgres if you didn't modify it), visit the Configuration tab and look for the Master username field under the Availability heading:
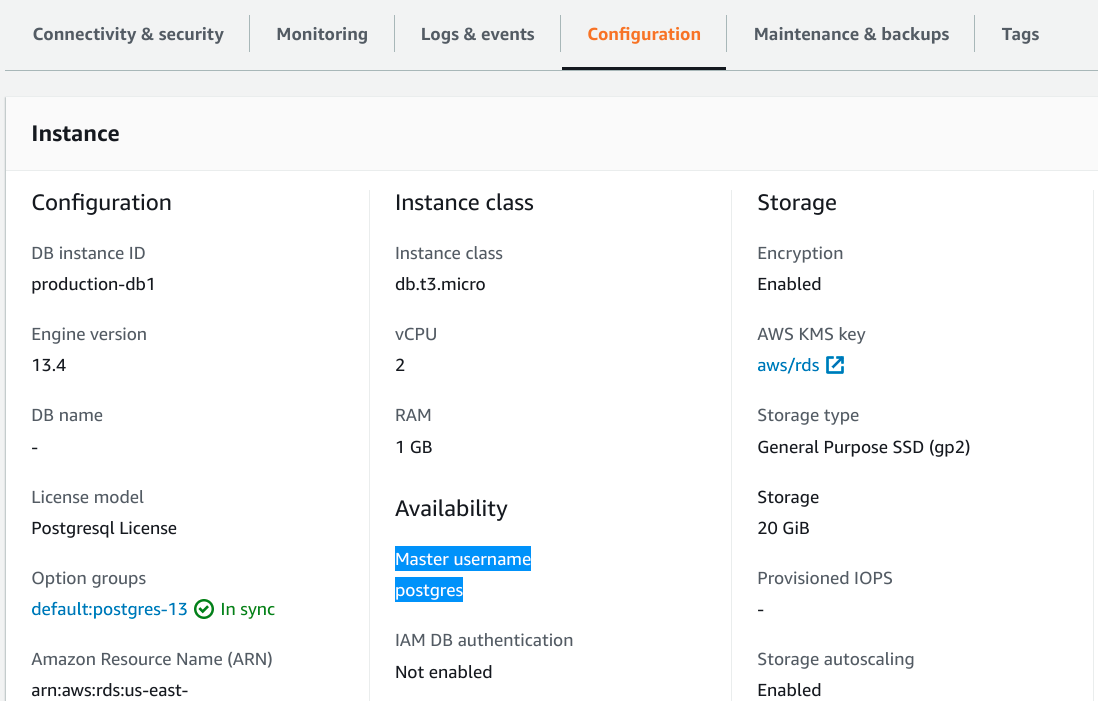
You can also find the name of the initial database on the left-hand side of this same tab, if you configured one.
With this information, you can connect to your PostgreSQL instance. For an example, to connect to the instance displayed here, you could use the following connection URI:
You can learn more about how to construct connection URIs from connection details in our guide on PostgreSQL connection URIs.
Conclusion
In this guide, we covered how to create a production-worthy PostgreSQL database instance using Amazon's RDS managed database service. While there are a lot of options to explore and your selections will vary based on the needs of your project and your environment, we attempted to provide a reasonable starting point here and enough information for you to make informed decisions.
As your needs change, keep in mind that you can scale your database instance to accommodate your new usage patterns. Use the data you collect from your monitoring information and the scaling logs to decide on how your database needs are evolving.
Once you've configured your PostgreSQL instance on Amazon RDS, you can connect to it and manage it using Prisma Client. Configure access to your database instance by setting the url parameter in the PostgreSQL database connector settings to point to your RDS instance.
