Serverless architecture
Traditional databases vs serverless databases
Introduction
The role of databases within many organizations has evolved over time. While reliance on data to build applications, make business decisions, and provide value in larger ecosystems has increased, the management of the database software and infrastructure itself has, in many cases, shifted.
While these assets have traditionally been operated by the organization itself, their management has increasingly been outsourced to external providers. The first iteration of this idea was to move to managed databases, where a provider manages the infrastructure and software while allowing the user to adjust settings and set scaling policies.
More recently, this idea has evolved to serverless databases, where the entire infrastructure, data storage, and underlying architecture is entirely managed by the provider and the user only accesses the data they manage through API-like interactions.
In this guide, we'll talk about the differences between traditionally deployed databases and their serverless counterparts. We will discuss managed database offerings where appropriate to help distinguish between the different options providers offer. Learning about these different concepts can help you understand the trade-offs between different offerings and make an informed decision about what type of database management would make sense for your own projects.
Checkout the Prisma Data Platform to manage all of your application data in a single place.
Traditional databases vs managed databases vs serverless databases
Before we dive into the advantages and disadvantages of various strategies, let's take a moment to review how the general idea behind how each system works.
Traditional databases
Traditional databases are the style of databases and database management that has been available for decades. It involves provisioning a physical or virtual server with the appropriate hardware resources and setting it up as a database server. Beyond the initial installation and configuration, this type of setup requires:
- ongoing management of the underlying infrastructure including hardware health, resource management, and network access
- maintaining an up-to-date, stable, and secure operating system, and
- configuring, optimizing, and managing the database management system
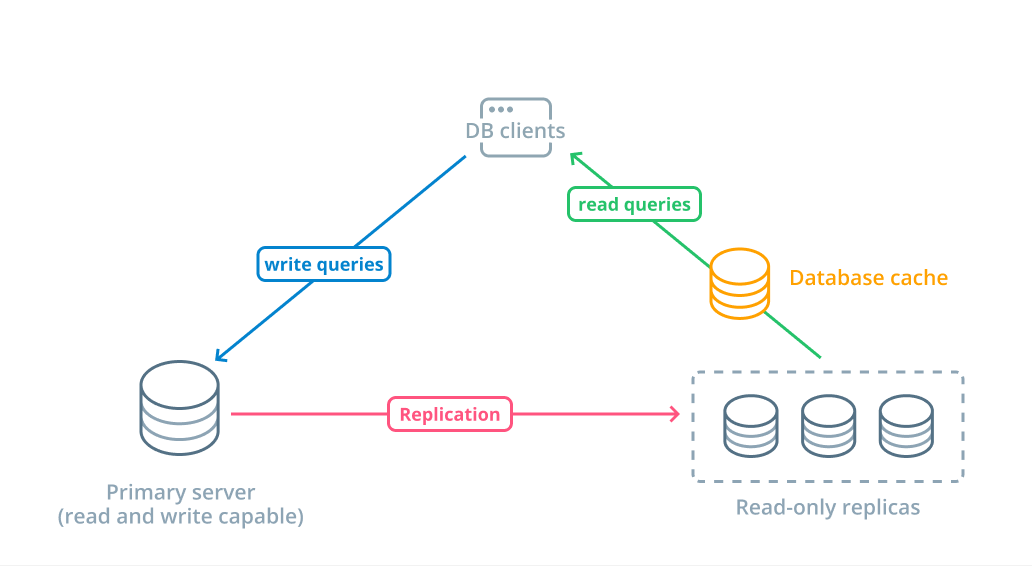
In general, this option provides enormous amounts of control and flexibility. Every part of the system can be examined, optimized, and changed to suit the needs of the users and applications.
This comes at the cost of a greater management burden. All levels of the system must be maintained and optimized to provide ideal application performance while maintaining the availability and security of the system and data.
Managed databases
Managed databases are a product offered by most cloud providers as an alternative to managing your own infrastructure. Instead, the provider manages the server configuration and database software and exposes options to the user to allow them to configure and tweak the behavior.
With managed databases, the provider takes responsibility for:
- ongoing management of the underlying infrastructure including hardware health, resource management, and network access
- maintaining an up-to-date, stable, and secure operating system, and
- managing parts of the database system like the health and functionality of database management system
The user is still responsible for:
- making decisions about the optimal settings for their database
- setting policies for scaling, backups, and other software-level configuration
Generally, this configuration allows the provider to manage the parts of the process that organizations don't particularly care about so long as they are maintained to a high standard. The key configurable areas are still exposed to the user so that they can tune behavior depending on the importance of the resource, operational requirements, and their SLAs.
Many organizations adopt this style of management because it allows their developers to customize the parts of the database they care about without having to maintain in-house system administration expertise. It can work well if your needs match well with what the provider had in mind for the product, but can be difficult when you find yourself struggling with the amount of control you are given or if the level of automation is still not what you had hoped for.
Serverless databases
Serverless databases are a relatively new approach offered by cloud providers that takes on an even larger part of the management responsibility from users. Serverless databases decouple the part of a database management system that deals with storage from the part that executes queries. This means both can be scaled independently. In serverless databases, these components are both managed exclusively by the provider.
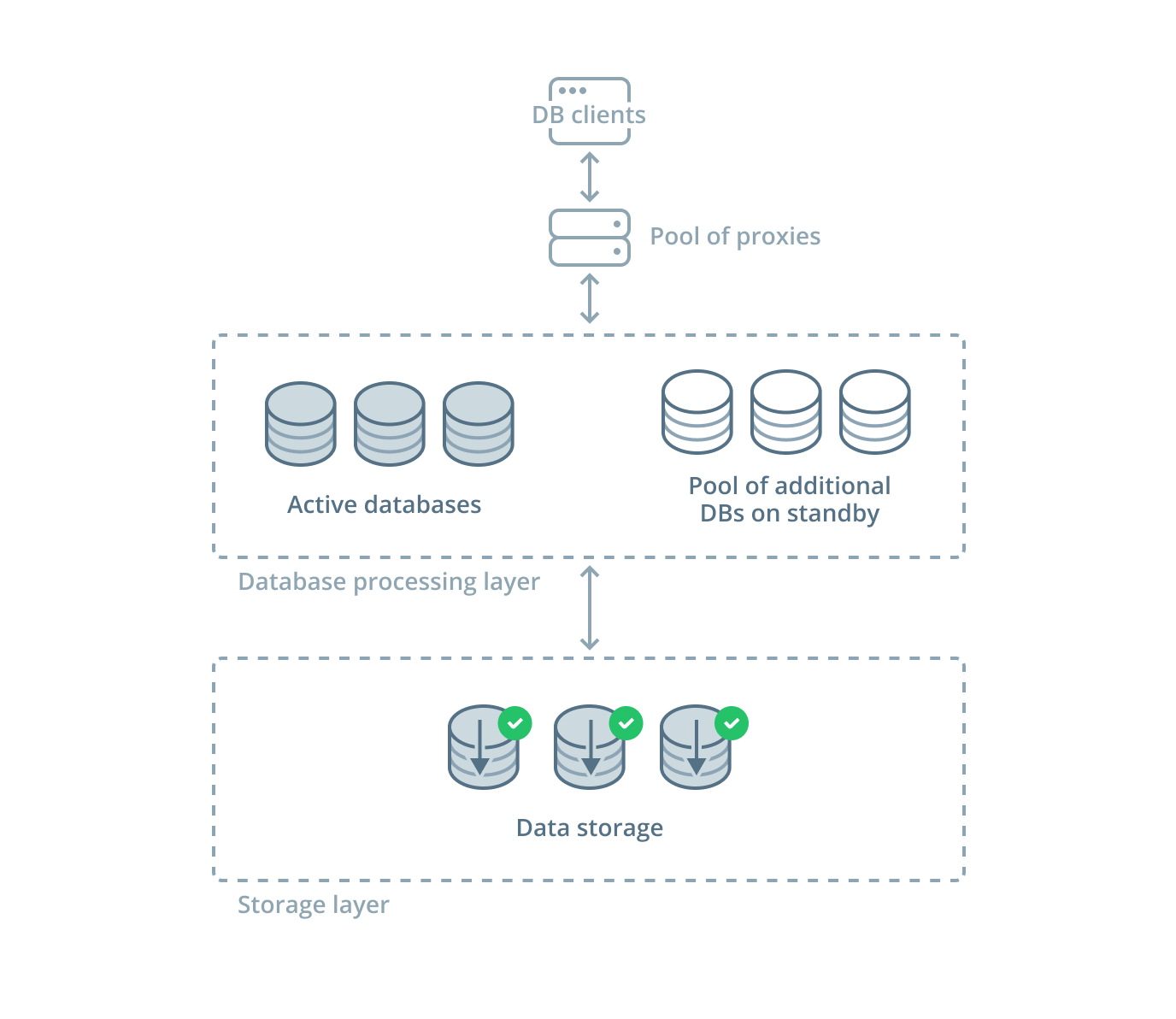
In practice, this allows serverless databases to be treated as an infinitely large repository where data can be stored, operated on, and retrieved. The backend storage will be scaled out as needed and the number of query executors will also be adjusted according to demand. The user only needs to access the database through an API-like interface that routes commands to the correct components automatically.
Serverless databases require the least amount of operational management of any of the options we've discussed. This allows you to use your database as if it were an external service rather than as a component of your infrastructure that you must keep operational.
When to use traditional databases and serverless databases
Now that we've reviewed the approaches taken by different database management strategies, we can talk about what scenarios they're best suited for. While these decisions will primarily come down to your own application requirements, internal expertise, and appetite for optimization and management, there are some general indicators to look for that may help point you in the right direction.
Why would I want to use a traditional database?
The traditional approach of managing the entire stack of your database server from hardware to database software is best suited if you need control, privacy, and performance.
High level of control
While a conventional database server requires continual monitoring, maintenance, and contingency planning to maintain availability, it offers unparalleled levels of control.
You can choose the infrastructure architecture that suits your specific needs, from a single server to a complex cluster. You can deploy these assets where ever you want, whether on premises, in data centers with your own or rented hardware, or by using standard compute assets from cloud providers. You can upgrade and swap out any components as you see fit and tweak any software-level configuration with no boundaries.
If it is important to you to have the power to change anything at any level of your deployment, then traditional database deployments are probably your best choice. You will have to pay for this level of control by taking responsibility for managing every part of your deployment.
Data privacy focused
If your application data requires very high levels of privacy, either as a feature or as a requirement to conform to any standard or regulation, traditional databases give you the most amount of control. You will be able to dictate exactly who has access to the physical hardware where they are deployed as well as any software-level access.
Running your own database servers can ensure that you can put the necessary levels of protection in place for your users and data. The data for different clients can be placed in different databases, on different servers, or in different physical locations to maintain strict separation. You can decide on deploying to data centers that meet certain industry standards to ensure that physical access is restricted.
On the software level, you also start from a place with no external access. No other parties have management oversight to your services by default. You can protect your data by refraining from providing access and by setting up encryption and other safeguards to provide the level of protection you require.
High performance
If your application requires consistent high performance, a conventional database deployment might be your best strategy.
When running database servers yourself, you can spot and mitigate contention for resources more easily since you have complete insight into the processes and clients competing. You don't have to worry about neighboring customers taking too much of a shared resource and you can provision additional assets as necessary. The peak performance of your system is limited only by the time and money you allocate and your expertise in managing your systems.
Especially relevant when comparing to serverless databases is the continual availability of your server database resources. You do not have cold start problems as you are not scaling down layers of your infrastructure whenever you fall below peak demand. This can be important if you require consistent performance regardless of the previous level of activity.
Why would I want to use a serverless database?
Serverless databases also have a significant number of advantages if they fit your use case well. They are a great choice if you want affordable database access that self-scales without a heavy management burden.
Low cost operation
One of the primary advantages that serverless databases can provide is a low cost of operation. Because both the storage and the computational layer of the serverless database scale independently, you only pay for exactly what you're using.
The storage layer scales according to how much data you are managing. This is usually priced according to volume, making the pricing relatively predictable if your application has consistent patterns. Because this storage backend is dynamically allocated, you never have to worry about running out of space or the costs associated with overprovisioning storage. The price reflects your storage only.
The computational layer is completely decoupled and scales using its own criteria. The number of query executor instances provisioned is determined by the current traffic that your application is passing to the databases. This means that in times of peak traffic, the service will spin up additional query processors to handle the requests. On the other hand, when no queries are being executed, the service can scale this layer down to zero, removing the cost of processing entirely during that time.
If you are very cost sensitive, serverless databases may be a good option because you don't need to worry predicting your usage exactly. The platform's resources and your costs scale exactly in line with your usage.
High scalability
We mentioned this as a function of costs in the last section, but one of the most significant advantages to a serverless database strategy is the ability to scale out easily. This not only affects expenses, but also your ability to meet varying levels of demand as your usage fluctuates over predictable cycles or changes due to spikes in interest.
The separate scaling mechanisms for data storage and query execution allow you to handle very different usage scenarios using the same service and configuration. The service can automatically adjust to accommodate most levels of usage and can grow with your application without any change to the database service.
High scalability also means that you can experiment with applications easily and move from testing to production without changes to your database service. You can set up testing and staging databases that will scale down to zero when not in use. This can be especially useful when practicing continuous integration and continuous delivery because your pipelines can use a database service that perfectly mirrors your production environment while only paying for the small amount of usage your tests require.
Reduced management responsibility
Perhaps the biggest highlight for serverless databases is the way they can help offload management responsibilities from your team. While many organizations have gotten use to the level of administrative overhead required by managed databases, serverless databases take on additional levels of support and management to further reduce your workload.
Serverless database services not only manage the infrastructure and database management system software, they also manage resource allocation and many of the policies for your databases. Instead of having to figure out exactly how much storage your database requires or how many database instances are required to serve your average traffic levels, the system can just respond to the conditions it finds. Instead of managing scaling rules, you can instead just set boundaries for the levels of scaling you desire and the platform will intelligently scale within those constraints.
This sounds similar to how managed databases are often described, but in practice it ends up being significantly different. You don't have to make many decisions ahead of time with serverless databases. Mainly, you configure any thresholds for costs that you want to maintain and any specific tweaks to the scaling you want to make, like always having at least one query executor available, for instance. The system handles nearly everything else to ensure that your application's database usage is always available, performing up to standards, and responding to the current request environment.
Conclusion
| Features | Traditional Databases | Serverless Databases |
|---|---|---|
| Level of control | High | Minimal |
| Data privacy | Private by default, configurable by administrators | Must trust provider with data |
| Performance | Capable of very high performance, depending on hardware and configuration | Performance can dip if there are spikes in demand (can be mitigated with query processors on standby) |
| Cost | Static, the database costs the same whether under high demand or not | Variable, pay only for what you use |
| Scalability | Depends on configuration, can be complex | Automatic scaling based on demand and service settings |
| Responsibility for management | Responsible for everything | Minimal responsibility |
In this article, we took a look at some of the key differences between traditional, self-managed databases and serverless database services. We talked about how they are different from a user's perspective and what trade-offs you must consider when deciding on a database strategy depending on your organization's priorities.
While serverless databases are not suitable for every type of application, they can make database management and operation significantly easier for many organizations. Understanding when they might be a good solution and what shortcomings they might have can help you figure out if they can and should be considered when evaluating database solutions.
Prisma's Data Proxy, now in early access, is one way to handle connection issues between your serverless applications and backend databases. It can help manage ephemeral connections from your serverless functions to avoid exhausting your database connection pool. Check it out now!
