Database types / Relational Databases
Using the expand and contract pattern for schema changes
Introduction

Database schema designs inevitably evolve over time as the software that interacts with the database change. It is important to be able to transition your schemas to incorporate new requirements as they arise in a safe and reliable manner.
While database migration software can often be used to update the actual data structures, the data itself must also be converted to new formats, migrated to different tables or columns, and updated to conform to new expectations. These processes, while not always complicated, are especially sensitive when performed on live systems that are actively being used by clients.
Fortunately, a multi-step process known as the expand and contract pattern can be applied to safely migrate clients to use new data structures incrementally without taking the system offline. In this guide, we will explore what the expand and contract pattern is, how it enables seamless transitions between new and old structures, and how to apply it to various database transformations.
What is the expand and contract pattern?
The expand and contract pattern is a process that database administrators and software developers can use to transition data from an old data structure to a new data structure without affecting uptime. It works by applying changes through a series of discrete steps designed to introduce the new structure in the background, prepare the data for live usage, and then switch over to the new structure seamlessly.
This process can be used to make changes to many in-use interfaces, but it is especially helpful for database schema changes. Beyond just migrating data and clients to a new data structure, the expand and contract pattern is also helpful in that it allows you to rollback changes easily at most points in the process if something doesn't go as planned or if your requirements change.
How to use the expand and contract pattern
In this section, we'll outline how you actually use the expand and contract pattern and what it is able to achieve. The individual steps involve coordination between the client applications and the schemas being used within the database. It is important to understand both the purpose of each step as well as the reason why it should be applied independently of its siblings.
Note: The order in which you execute steps 2 and 3 depends on your requirements, design, and preferences. Many times, it is appropriate to expand the client interface prior to migrating data, but it can be useful to migrate the data before altering any client behavior in some cases.
Step 1: Build and deploy the new schema
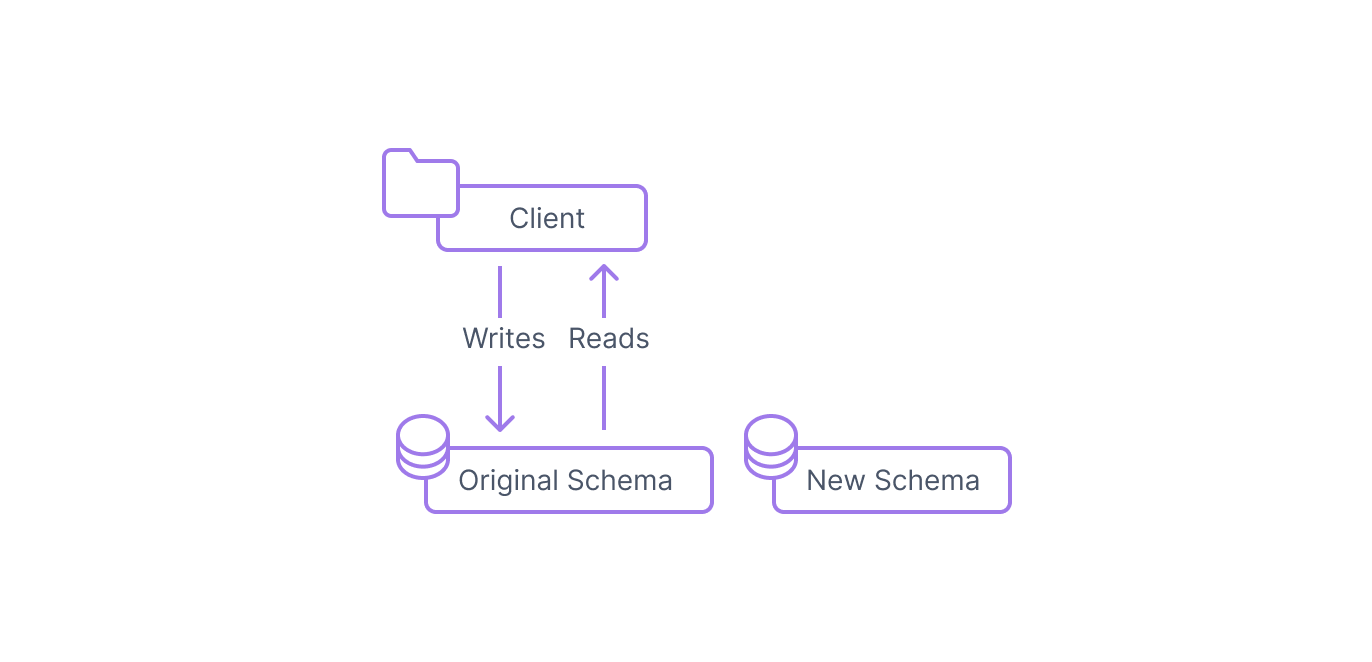
The first step in the expand and contract pattern is to design a new schema that satisfies your new requirements. Ideally, this should involve small changes to the existing structure. Larger changes should be broken up into smaller, isolated steps which can each run through this process in succession.
Because the existing structure is currently being used by clients, you cannot directly alter any columns directly. Instead, you need implement your changes in parallel with the existing structure. For example, if you want to split a name column into first_name and last_name, you should add both of the new columns instead of modifying the name column.
For column-level changes, this often means adding new columns to a table that have the characteristics you want while leaving the current columns as-is. For more complicated changes, this can mean creating a completely new table that represents the new data structure.
Deploy the data structure that represent your new design to your database. Make sure that any new columns do not have any constraints that would make the current client behavior fail. For instance, you will probably need to make your new columns nullable and/or provide default values.
At this point, the database clients should be able to access the original structures the same as they always have.
Step 2: Expand the interface
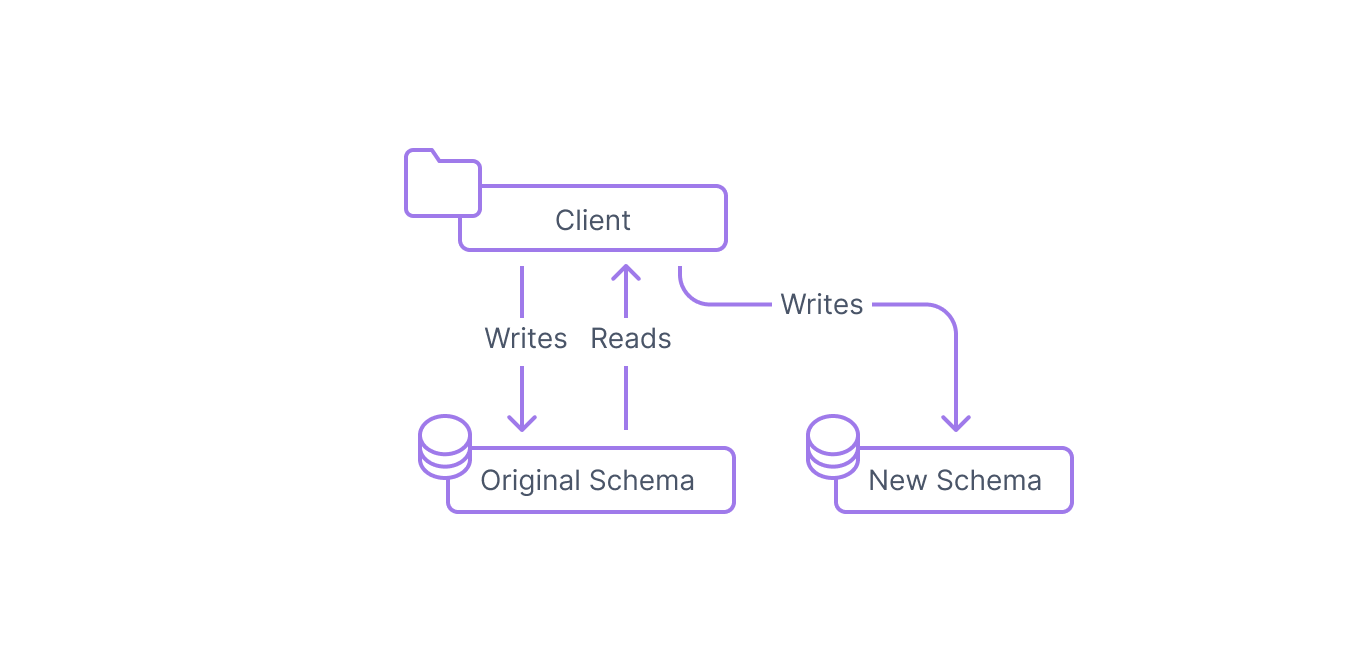
After deploying the new database schema alongside the original schema, the next step is to expand the interface of the clients to recognize the new columns and tables. The client code will still read all of its values from the original data structure. However, when performing write operations, the client will now add or modify data in both the original structure and in the new structure.
The client is now actively inserting data into the new structure alongside the original structure. This gives you the opportunity to validate the new interface between the two components and ensures that all data going forward will be persisted in the new data structure. Because the client continues to write to the old structure and because any read operations still exclusively reference the original structure, the external behavior of the client should remain exactly the same.
Step 3: Migrate existing data to the new schema
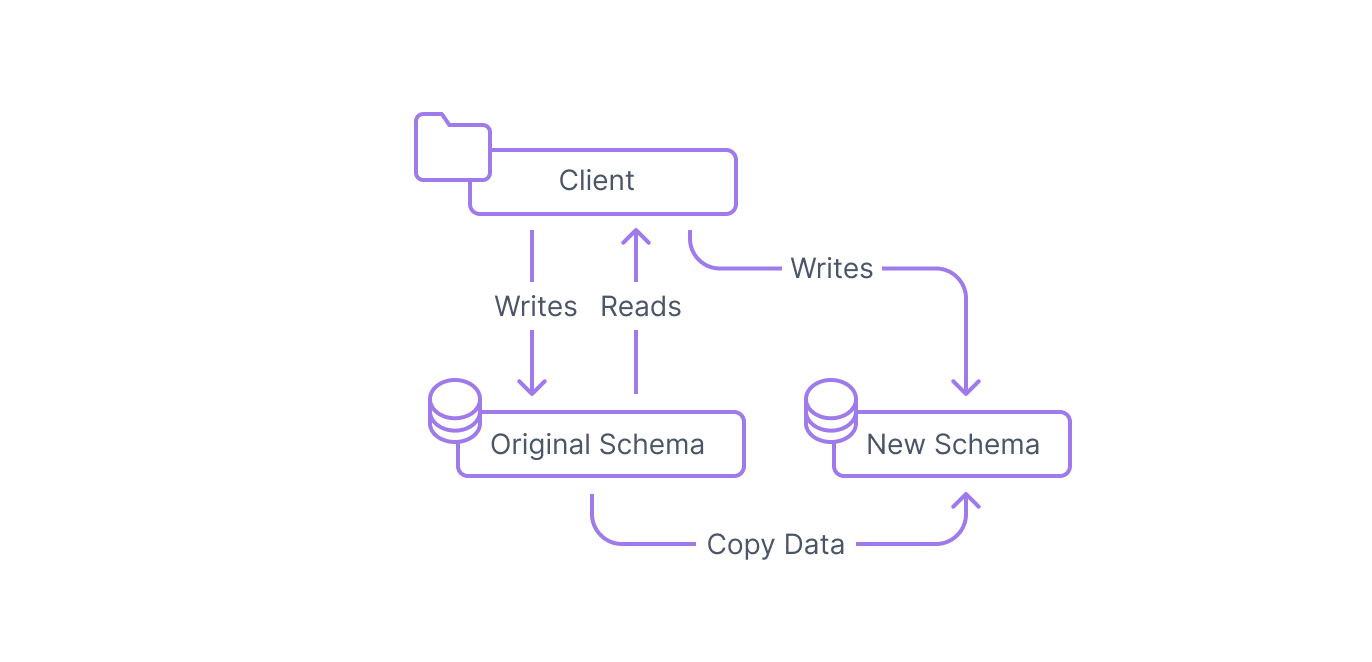
The new data schema is in place within the database, but it does not yet have any of the actual data that the original schema holds. To prepare the new schema for actual use, you need to migrate the data from the existing columns or tables to the new ones.
In some cases, this step may require just copying the existing values to the new structure, but often, you may need to modify the data in some way to account for the differences between the two schemas. This might involve modifying data types, splitting up values, backfilling default values, and more.
It is essential to think carefully about this step to ensure that the changes you are making are correct and semantically equivalent to their original meaning. Sometimes, this will be obvious. For example, if your original color column stored values as a string and the new column instead stores an ID that corresponds to colors stored in another table, the mutation should be fairly straightforward.
Other times, however, it might be less clear. For example, if you have a name column that you hope to split into first_name and last_name, it may be unclear where the division between those two components lies. For example, while you could probably confidently guess how to split "John Smith", your data migration script may not do the right thing with "Juan Carlos Ferdinand Garcia". Take extra time to think about the new fields relate to the original fields and whether your system requires new information to correctly migrate some records.
To perform migrations with Prisma, you can use the Prisma Migrate. Developing with Prisma Migrate generates migration files based on the declarative Prisma schema and applies them to your database.
Step 4: Test the new interface
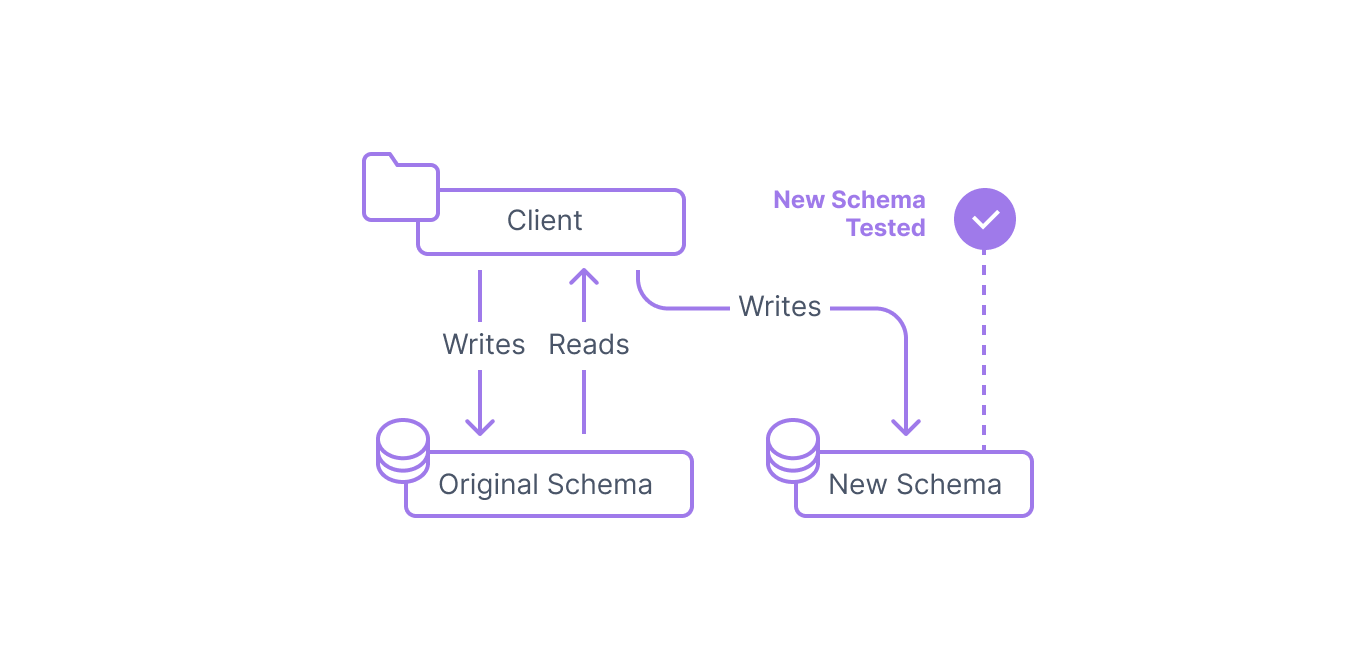
Once your data has been migrated and your client is writing to both the original and new structures, you have the opportunity to test the new interface. While the production clients are still using the original data structure as their source of truth, you can run queries and clients in parallel to validate that the new structure works as intended.
This stage often involves functional testing to ensure that the new structure can run all of the queries that the production clients require and produce the expected results. Performance is another area that should be tested if possible, though you may run into trouble if you try to test on the same servers actively supporting production traffic. Testing on a standby or replica server may be an option in this case. If performance is not adequate, you may need to build new indexes or modify your queries.
This is your last opportunity to validate the behavior of the new interface before it will be used for production traffic. Ensure that you are confident that it satisfies your requirements before continuing.
Step 5: Cut reads over to the new interface
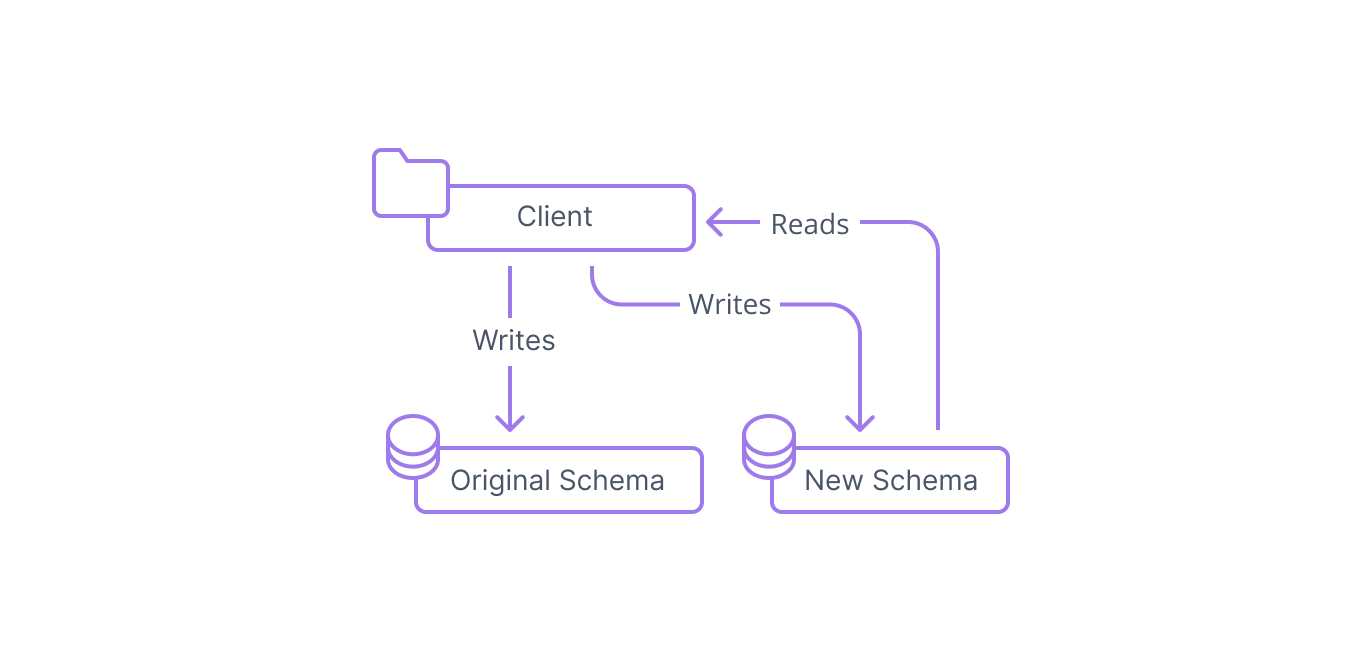
At this point, you are ready to actually begin transitioning production traffic to the new database structure. This means modifying the client behavior to use the new schema for reads instead of the original schema.
This step represents the cut over that finally migrates your traffic. The new structure will be entirely responsible for handling production requests, though the clients will continue to write to both data structures.
Depending on the nature of your schema change, this might also represent the first time where you are in danger of losing data if you have to roll back. While the old data structure is still receiving writes from your clients, it will not store any data unique to the new design. If you decide you need to transition back to the old design, unique data collected in the new table will be lost or unable to be incorporated without additional work.
In practice this step is usually performed in stages to transition multiple clients over in a controlled fashion. We will discuss some strategies that help with this process later on.
Step 6: Discontinue writing to the original structure
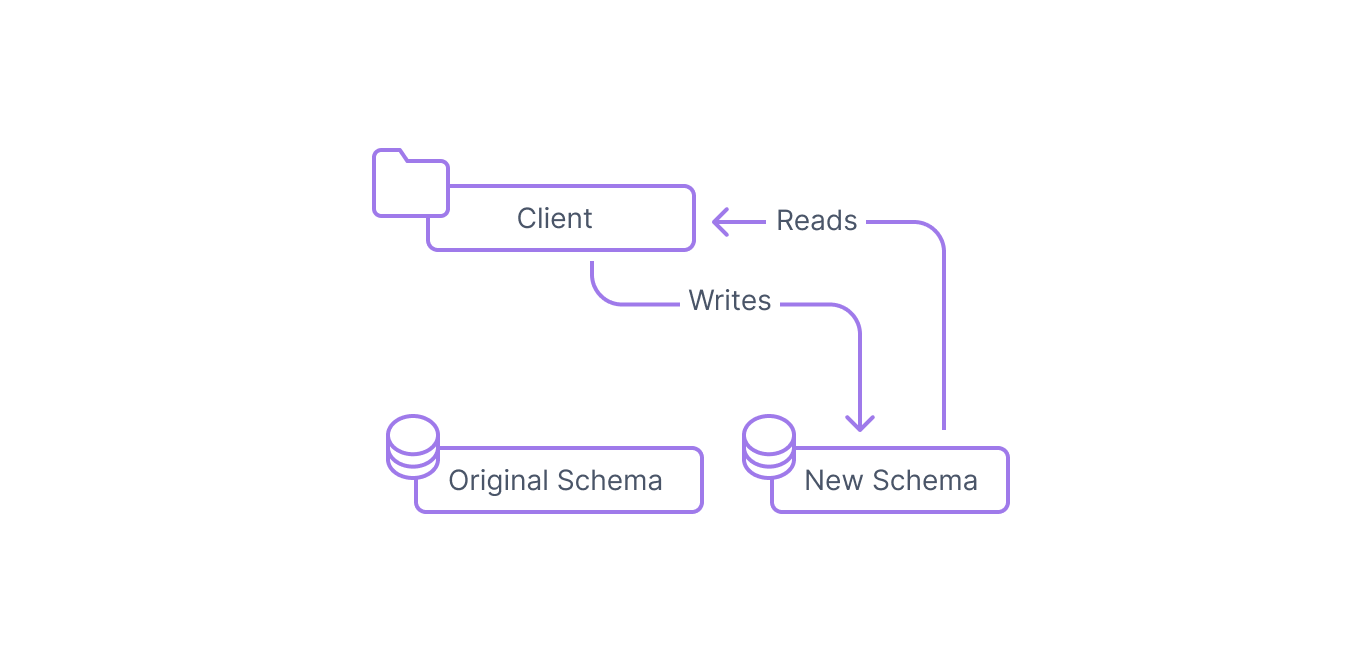
Once you've confirmed that your new structure is working as intended, you can stop writing to the original structure by once again updating the database clients.
The new schema exclusively is now used by the clients.
Step 7: Remove the original structure from the system
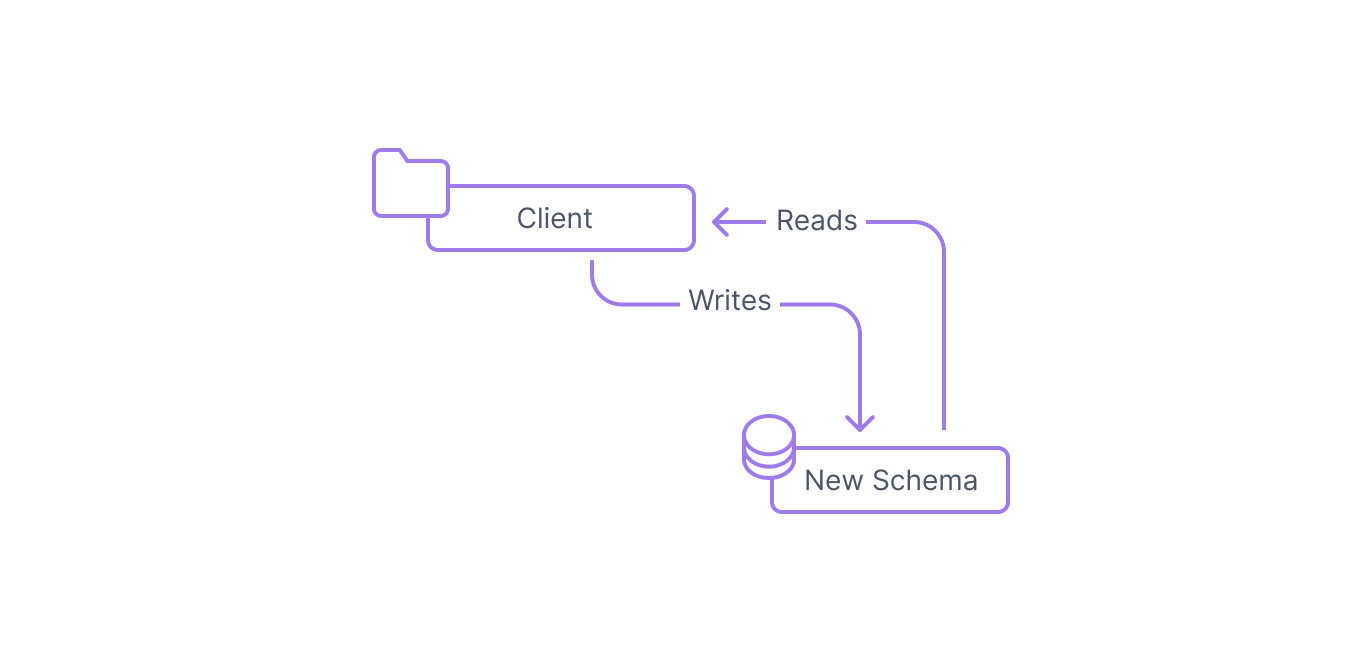
Once all clients have been updated to stop writing to the original schema, you can safely delete the original data structure. This is the last step of the expand and contract pattern that completes the migration to the new structure.
Example of the expand and contract pattern
To better illustrate how you can use the expand and contract pattern to implement changes to your data schema, migrate your data, and reconfigure clients without downtime, we'll demonstrate how to apply this strategy in an example.
Imagine you have a table called equipment that is used to catalog playground equipment used throughout a park district. The table has the following columns:
Currently, the equipment table tracks where a piece of equipment is installed through the city, park, and playground columns (with the playground column being used to specify the exact playground when a park has multiple playgrounds). However, it becomes apparent that this information is better tracked in a separate table. The new design calls for a table that looks like this:
To implement this change, the team creates a new playground table to house the information related to a specific playground within a specific park. This will hold all information related to a playground to keep it separate from the information related to equipment.
The first step the team takes is to create the new playground table beside the original equipment table:
Next, the client application is updated to write any new playground-related data to both the equipment table and the playground table by configuring the application to write to all tables returned by the feature flag DATABASE:equipment_location:write defined as a list on their Redis server. While they are adding this change, they also implement another feature flag that checks the value of DATABASE:equipment_location:read to determine which data source to read from.
After the change to the client code, the most recent two records are recorded in both locations:
Table equipment:
| id | item_type | installed_at | city | park | playground |
|---|---|---|---|---|---|
| 1 | "slide" | 2018-12-30 | "Westfield" | "Gloria Maynard Park" | 1 |
| 2 | "swing" | 2016-05-07 | "Westfield" | "Gloria Maynard Park" | 1 |
| 3 | "seesaw" | 2012-08-18 | "Westfield" | "Gloria Maynard Park" | 2 |
| 4 | "swing" | 2015-02-17 | "Westfield" | "Gloria Maynard Park" | 2 |
| 5 | "swing" | 2019-04-02 | "Westfield" | "Clear View Park" | 4 |
| 6 | "seesaw" | 2017-08-03 | "Westfield" | "Clear View Park" | 5 |
| 7 | "slide" | 2014-07-03 | "Fairmont" | "Lincoln Woods" | 6 |
| 8 | "monkey bars" | 2019-11-22 | "Fairmont" | "Lincoln Woods" | 6 |
| 9 | "merry-go-round" | 2018-07-28 | "Fairmont" | "Lincoln Woods" | 7 |
| 10 | "merry-go-round" | 2021-03-18 | "Westfield" | "Clear View Park" | 4 |
| 11 | "swing" | 2021-03-18 | "Fairmont" | "Lincoln Woods" | 6 |
Table playground:
| id | city | park | sq_ft |
|---|---|---|---|
| 4 | "Westfield" | "Clear View Park" | 200 |
| 6 | "Fairmont" | "Lincoln Woods" | 180 |
Since all new data is being recorded to both locations, the team can focus on migrating the older data to the new structure. They develop a script that pulls the existing records from the equipment table to populate the playground table. The script additionally references an external source to fill in the size of each park in square feet. The result looks something like this:
Table equipment:
| id | item_type | installed_at | city | park | playground |
|---|---|---|---|---|---|
| 1 | "slide" | 2018-12-30 | "Westfield" | "Gloria Maynard Park" | 1 |
| 2 | "swing" | 2016-05-07 | "Westfield" | "Gloria Maynard Park" | 1 |
| 3 | "seesaw" | 2012-08-18 | "Westfield" | "Gloria Maynard Park" | 2 |
| 4 | "swing" | 2015-02-17 | "Westfield" | "Gloria Maynard Park" | 2 |
| 5 | "swing" | 2019-04-02 | "Westfield" | "Clear View Park" | 4 |
| 6 | "seesaw" | 2017-08-03 | "Westfield" | "Clear View Park" | 5 |
| 7 | "slide" | 2014-07-03 | "Fairmont" | "Lincoln Woods" | 6 |
| 8 | "monkey bars" | 2019-11-22 | "Fairmont" | "Lincoln Woods" | 6 |
| 9 | "merry-go-round" | 2018-07-28 | "Fairmont" | "Lincoln Woods" | 7 |
| 10 | "merry-go-round" | 2021-03-18 | "Westfield" | "Clear View Park" | 4 |
| 11 | "swing" | 2021-03-18 | "Fairmont" | "Lincoln Woods" | 6 |
Table playground:
| id | city | park | sq_ft |
|---|---|---|---|
| 4 | "Westfield" | "Clear View Park" | 200 |
| 6 | "Fairmont" | "Lincoln Woods" | 180 |
| 1 | "Westfield" | "Gloria Maynard Park" | 500 |
| 2 | "Westfield" | "Gloria Maynard Park" | 380 |
| 5 | "Westfield" | "Clear View Park" | 850 |
| 7 | "Fairmont" | "Lincoln Woods" | 444 |
Both tables are now up-to-date. It is important to note, however, that the new playground table does contain information not stored in the equipment table (the sq_ft column). If you were to roll back changes at this point, you would be able to return to your previous table state, but you would lose the data that's been captured for each playground's size.
When they are ready, the team changes the value of the DATABASE:equipment_location:read variable on their Redis server to point to get location information from the new playground table. Their client application begins reading only the equipment-related information from the equipment table. It uses the new playground table to pull all location information.
Once they are confident that everything is working correctly, they can modify the DATABASE:equipment_location:write variable to remove the equipment table from the list of write targets. Finally, they can remove the legacy columns from the equipment table to clean up their schema and complete their work:
Table equipment:
| id | item_type | installed_at | playground |
|---|---|---|---|
| 1 | "slide" | 2018-12-30 | 1 |
| 2 | "swing" | 2016-05-07 | 1 |
| 3 | "seesaw" | 2012-08-18 | 2 |
| 4 | "swing" | 2015-02-17 | 2 |
| 5 | "swing" | 2019-04-02 | 4 |
| 6 | "seesaw" | 2017-08-03 | 5 |
| 7 | "slide" | 2014-07-03 | 6 |
| 8 | "monkey bars" | 2019-11-22 | 6 |
| 9 | "merry-go-round" | 2018-07-28 | 7 |
| 10 | "merry-go-round" | 2021-03-18 | 4 |
| 11 | "swing" | 2021-03-18 | 6 |
Table playground:
| id | city | park | sq_ft |
|---|---|---|---|
| 4 | "Westfield" | "Clear View Park" | 200 |
| 6 | "Fairmont" | "Lincoln Woods" | 180 |
| 1 | "Westfield" | "Gloria Maynard Park" | 500 |
| 2 | "Westfield" | "Gloria Maynard Park" | 380 |
| 5 | "Westfield" | "Clear View Park" | 850 |
| 7 | "Fairmont" | "Lincoln Woods" | 444 |
Conclusion
In this guide, we discussed how the expand and contract pattern can be used as part of your toolkit to safely transition your database and its data to a new schema. We took a look at how the pattern works and what advantages it provides. Finally, we finished with an example to demonstrate how a database change may work in the real world.
The ideas presented in this guide are not unique, but they are powerful ways to systematically transition your database and its data while actively serving client requests. By implementing these strategies with careful thought, you can avoid many common problems and often achieve uninterrupted service for your clients.
For some guidance on how the expand and contract pattern can be used with Prisma Client, check out the matching section in Prisma's documentation on advanced migration scenarios.